第1页共36页编号:时间:2021年x月x日书山有路勤为径,学海无涯苦作舟页码:第1页共36页微信热门文章采集方法以及详细步骤本文将以搜狗微信文章为例,介绍使用八爪鱼采集网页文章正文的方法
文章正文里一般包括文本和图片两种
本文将采集文章正文中的文本+图片URL
将采集以下字段:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方式”功能,请大家注意)
同时,采集文章正文中的文本+图片URL,将用到“判断条件”,“判断条件”的使用,有很多需要注意的地方
以下两个教程,大家可先熟悉一下
“自定义数据合并方式”详解教程:http://www
bazhuayu
com/tutorialdetail-1/zdyhb_7
html“判断条件”详解教程:http://www
bazhuayu
com/tutorialdetail-1/judge
html采集网站:http://weixin
com/使用功能点:分页列表信息采集http://www
bazhuayu
com/tutorial/fylb-70
t=1Xpathhttp://www
bazhuayu
com/search
query=XPathAJAX点击和翻页http://www
bazhuayu
com/tutorial/ajaxdjfy_7
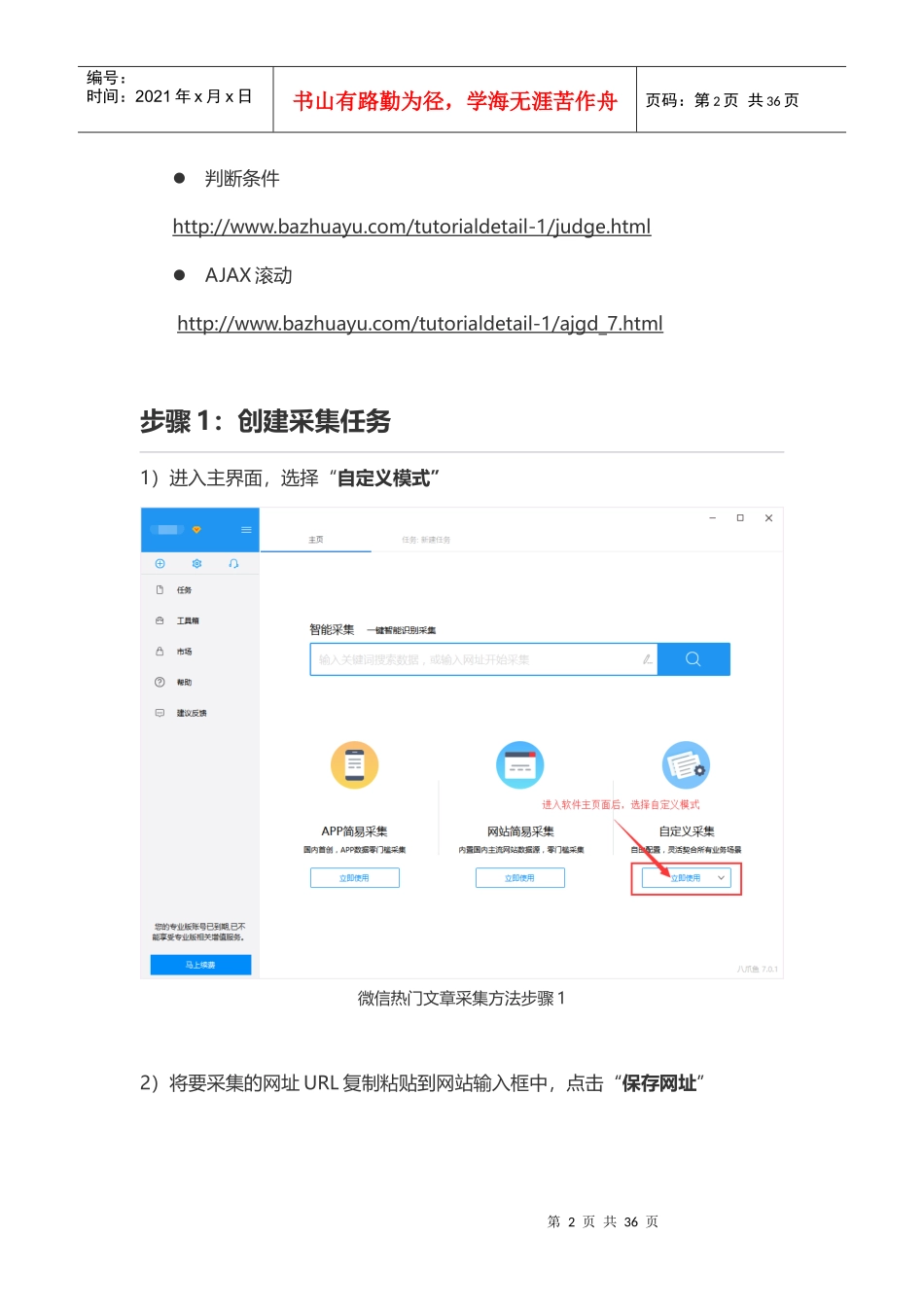
t=1第2页共36页第1页共36页编号:时间:2021年x月x日书山有路勤为径,学海无涯苦作舟页码:第2页共36页判断条件http://www
bazhuayu
com/tutorialdetail-1/judge
htmlAJAX滚动http://www
bazhuayu
com/tutorialdetail-1/ajgd_7
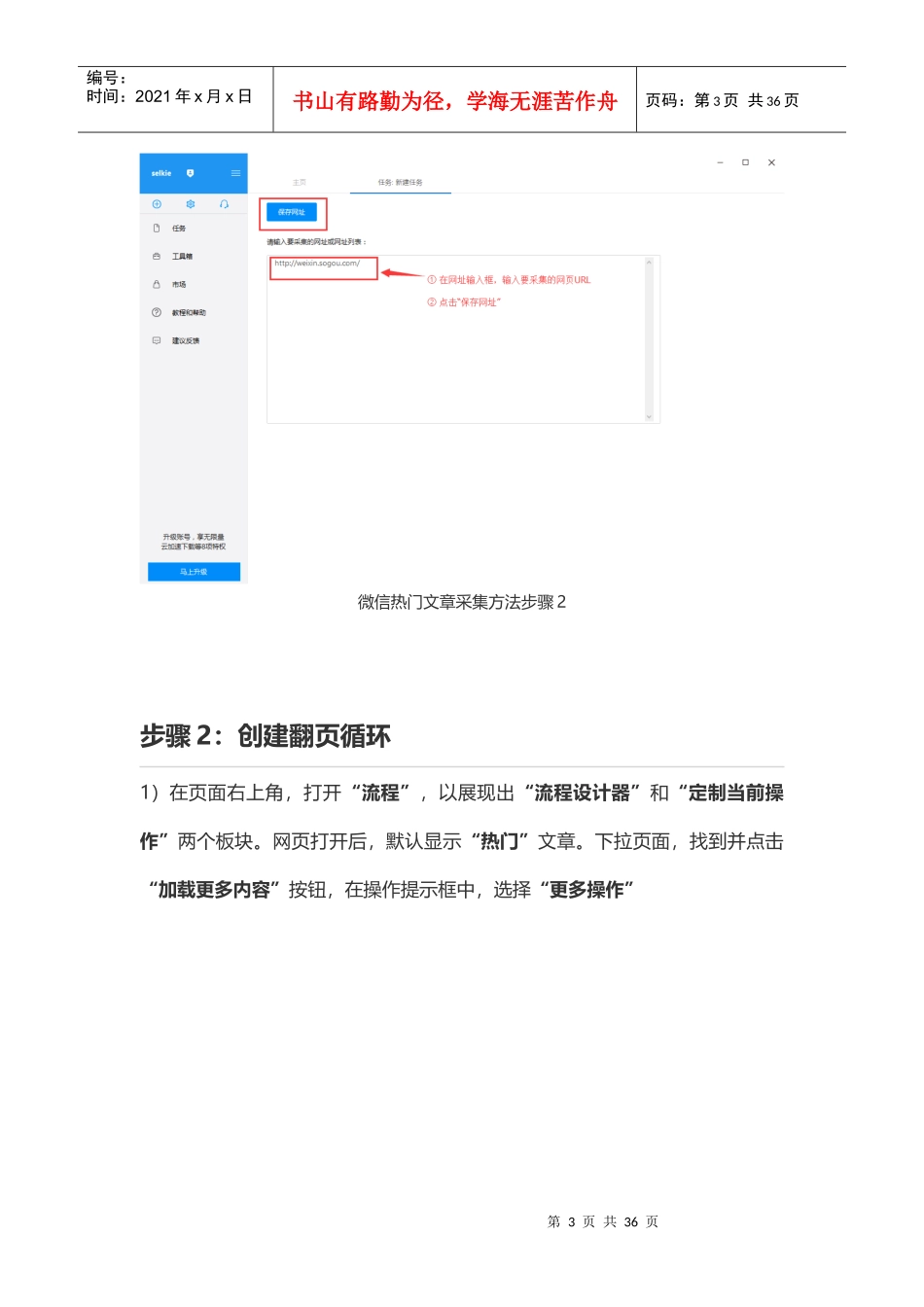
html步骤1:创建采集任务1)进入主界面,选择“自定义模式