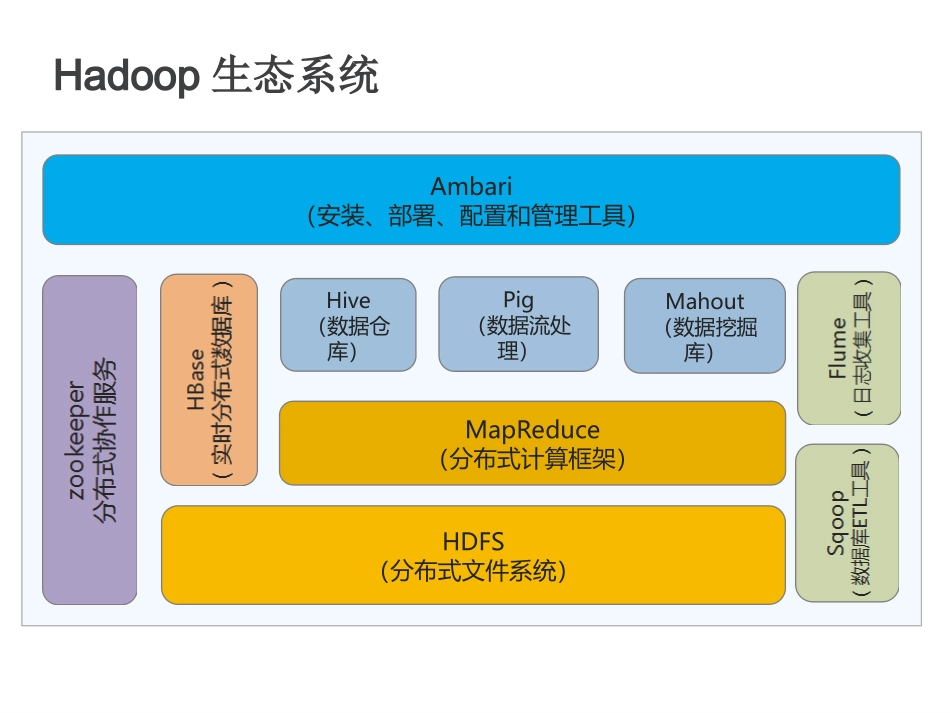
云软件组陈修恒SPARK大数据处理引擎Spark一、ApacheSpark项目三、Spark技术架构四、Spark核心技术五、部署方式六、运行流程七、配置要求Hadoop生态系统Ambari(安装、部署、配置和管理工具)Hive(数据仓库)Pig(数据流处理)Mahout(数据挖掘库)MapReduce(分布式计算框架)HDFS(分布式文件系统)ApacheHadoop项目CommonHDFS一个部署在廉价的机器上、具有高度容错性的文件系统YARN资源调度引擎MapReduce基于YARN调度引擎的大数据并行处理系统AYARN-basedsystemforparallelprocessingoflargedatasets.ApachSpark项目Spark是一个快速通用的大规模数据处理框架。具有Hadoop的批处理能力,而且性能更佳。可以用于流处理、Sql统计、机器学习和图计算。ApachSpark项目ApacheSparkTMisafastandgeneralengineforlarge-scaledataprocessingApacheSparkTM是一个快速、通用的大数据处理引擎ApacheSparkTM是HadoopMapReduce的改进版SparkVSHadoopMapReduceSparkHadoopMapRecuce架构Spark+RDDRDD:由Spark内部维护的、基于内存的分布式数据集MapReduce+HDFSHDFS:分布式文件系统工作量面向函数编程需要提供Map/Reduce函数。面向对象编程需要提供Map/Reduce类。数据处理RDD保存Map操作的结果,支持多次Map迭代。Map计算懒加载,用到时才发生计算Map、Reduce成对出现。Reduce结果落地后才能被下次Map使用故障处理多主多备集成HDFS不会有数据丢失,其他情况会有丢失情况;standalone启动模式Driver节点不能自动恢复,任务需要重新提交;依赖HDFS能快速恢复计算节点Spark技术架构Kafka/HDFS/TCP/Flume/ZeroMQ/MQTT/TwiterSparkRDDMapReduce函数式编程接口AmazonEC2/Mesos/YARN由Scala编写,支持函数式编程。支持多种数据源接入。RDD-弹性分布式数据集,Spark将数据分布到多台机器的内存中进行并行计算。Spark不具备集群管理能力,需要别的软件进行管理。支持流式运算,可以从kafka等数据源不断的获取数据,并按时间切片处理。Spark核心技术MapReduce编程模型SparkRDDSpark运行流程SparkTransformation&ActionSparkShuffleSparkStreamingSparkSQLSparkMllibSparkGraphXMapReduce编程模型任何运算都可以分解成"Map(映射)"和"Reduce(归约)"两类操作MapReduce编程模型词频统计tobeornottobeto:2be:2or:1not:1统计算法tobeornottobeMapReduce编程模型示例:词频统计to,be,or,not,to,be数据切割,,,,,构造运算单元,,,发生计算ReduceMapMapReduce代码预览to,be,or,not,to,be,,,,,,,,tobeornottobe输出结果MapReduce编程模型海量数据结算结果数据划分中间结果mapmapmapmap……(k1,val)(k2,val)(k2,val)(k1,val)(k2,val)(k3,val)(k1,val)(k2,val)(k3,val)aggregation&shufflereducereducereduce(k1,values)(k2,values)(k3,values)(K1,val)(K3,val)(K2,val)MapReduce编程模型任何运算都可以分解成"Map(映射)"和"Reduce(归约)"两类操作MapReduce编程模型任何运算都可以分解成"Map(映射)"和"Reduce(归约)"两类操作MapReduce系统数据划分和计算任务调度出错检测和恢复数据/代码互定位系统优化MapReduce的实现GoogleMapReduceHadoopMapReduceSparkSparkRDDRDD(ResilientDistributedDataset,弹性分布式数据集),他具高度的容错性,允许开发人员在大型集群上执行基于内存的计算。RDD是一个只读的分区存储集合。只能基于稳定物理存储中的数据集或在已有的RDD上执行转换命令(Transformation)来创建。RDD不需要物化。在创建RDD时Spark会维护转换算法。需要使用时,可以从物理存储的数据计算出最终的RDD。Spark操纵数据的一个高度抽象,是数据抽取和处理的基础。workerworkerworker——————Spark运行流程RDD(分布式数据集)第20/40页master注册任务注册任务clientsubmitdriverexecutorexecutor执行main作业解析生成Stage调度Task作业执行者接收Driver的LaunchTask命令可执行一个或多个Task作...