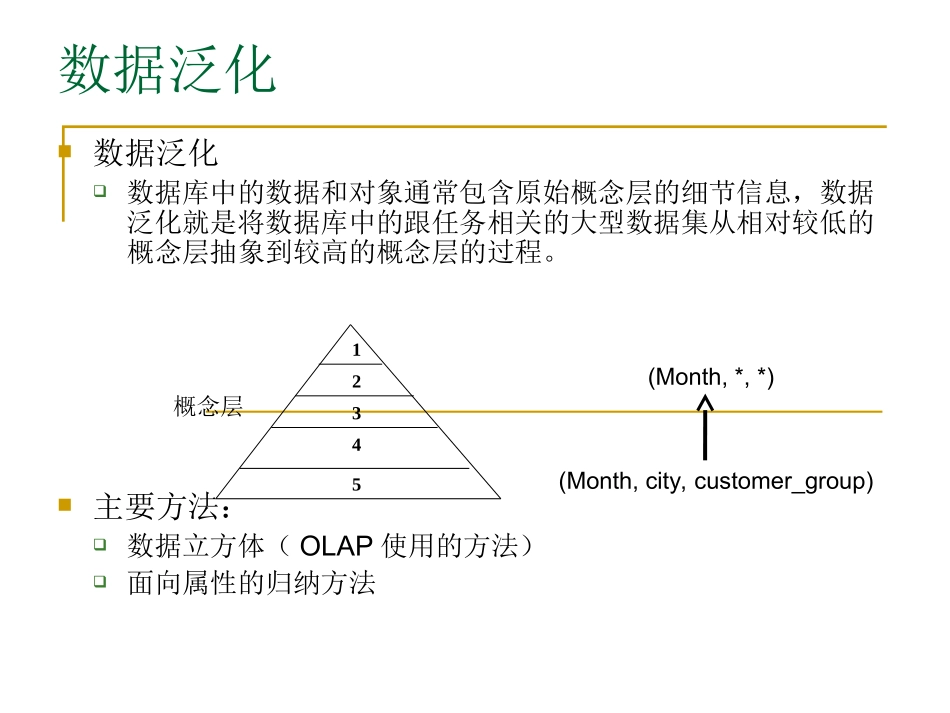
数据立方体计算与数据泛化数据泛化数据泛化数据库中的数据和对象通常包含原始概念层的细节信息,数据泛化就是将数据库中的跟任务相关的大型数据集从相对较低的概念层抽象到较高的概念层的过程
主要方法:数据立方体(OLAP使用的方法)面向属性的归纳方法12345概念层(Month,city,customer_group)(Month,*,*)两种不同类别的数据挖掘从数据分析的角度看,数据挖掘可以分为描述性挖掘和预测性挖掘描述性挖掘:以简洁概要的方式描述数据,并提供数据的有趣的一般性质
数据泛化就是一种描述性数据挖掘预测性数据挖掘:通过分析数据建立一个或一组模型,并试图预测新数据集的行为
g分类、回归分析等数据立方体的物化数据立方体有利于多维数据的联机分析处理数据立方体使得从不同的角度对数据进行观察成为可能方体计算(物化)的挑战:海量数据,有限的内存和时间海量数据运算对大量计算时间和存储空间的要求数据立方体---基本概念(1)数据立方体可以被看成是一个方体的格,每个方体用一个group-by表示最底层的方体ABC是基本方体,包含所有3个维最顶端的方体(顶点)只包含一个单元的值,泛化程度最高上卷和下钻操作与数据立方体的对应BA()CABACBCABC数据立方体---基本概念(2)基本方体的单元是基本单元,非基本方体的单元是聚集单元聚集单元在一个或多个维聚集,每个聚集维用"*"表示E
(city,*,year,measure)m维方体:(a1,a2,
,an)中有m个不是"*"祖先和子孙单元i-D单元a=(a1,a2,
,an,measuresa)是j-D单元b=(b1,b2,
,bn,measureb)的祖先,当且仅当(1)i=min_sup闭立方体(1)冰山方体的计算通过冰山条件(例:HAVINGCOUNT(