前言: 年前,在老大的号召下,我们纠集了一帮人搞起了Hadoop,并为其取了个响亮的口号“云在手,跟我走”
大家几乎从零开始,中途不知遇到多少问题,但终于在回家之前搭起了一个拥有12台服务器的集群,并用命令行在该集群上运行了一些简单的mapreduce 程序
想借此总结我们的工作过程
安装过程: 一、安装Linux操作系统 二、在Ubuntu 下创建 Hadoop 用户组和用户 三、在Ubuntu 下安装JDK 四、修改机器名 五、安装ssh 服务 六、建立 ssh 无密码登录本机 七、安装Hadoop 八、在单机上运行Hadoop 一、安装Linux 操作系统 我们是在windows 中安装linux系统的,选择的是 Ubuntu 11
10,介于有些朋友是第一次安装双系统,下面我就介绍一种简单的安装方法: 1、下载 Ubuntu-11
10-desktop-i386
iso 镜像文件,用虚拟光驱打开,执行里面的wubi
exe 程序,如图(1) 2、选择在 widows 中安装,如图(2) 3、在弹出的窗口中设置一些具体的参数,自动跟新完成后需要重启
重启时,就会出现 Ubuntu系统的选择了,系统一般默认开机启动 windows 系统,所以这里要自己手动选择哦~,进入 ubuntu后,系统就自动下载,跟新、安装了
(注:安装的过程中可能会卡在一个阶段很长时间(我卡了半个小时),这时我选择了强制关机,重启时同样选择进入 Ubuntu
一般第二次就不会卡,具体原因我也不是很清楚,可能和 wubi
exe程序有关吧
在网上看到,有些人认为用 wubi
exe 安装 ubuntu 不是很好,可能这就是它的不好之处吧
不过这是非常简单的方法,所以我们还是选择这种安装方法吧
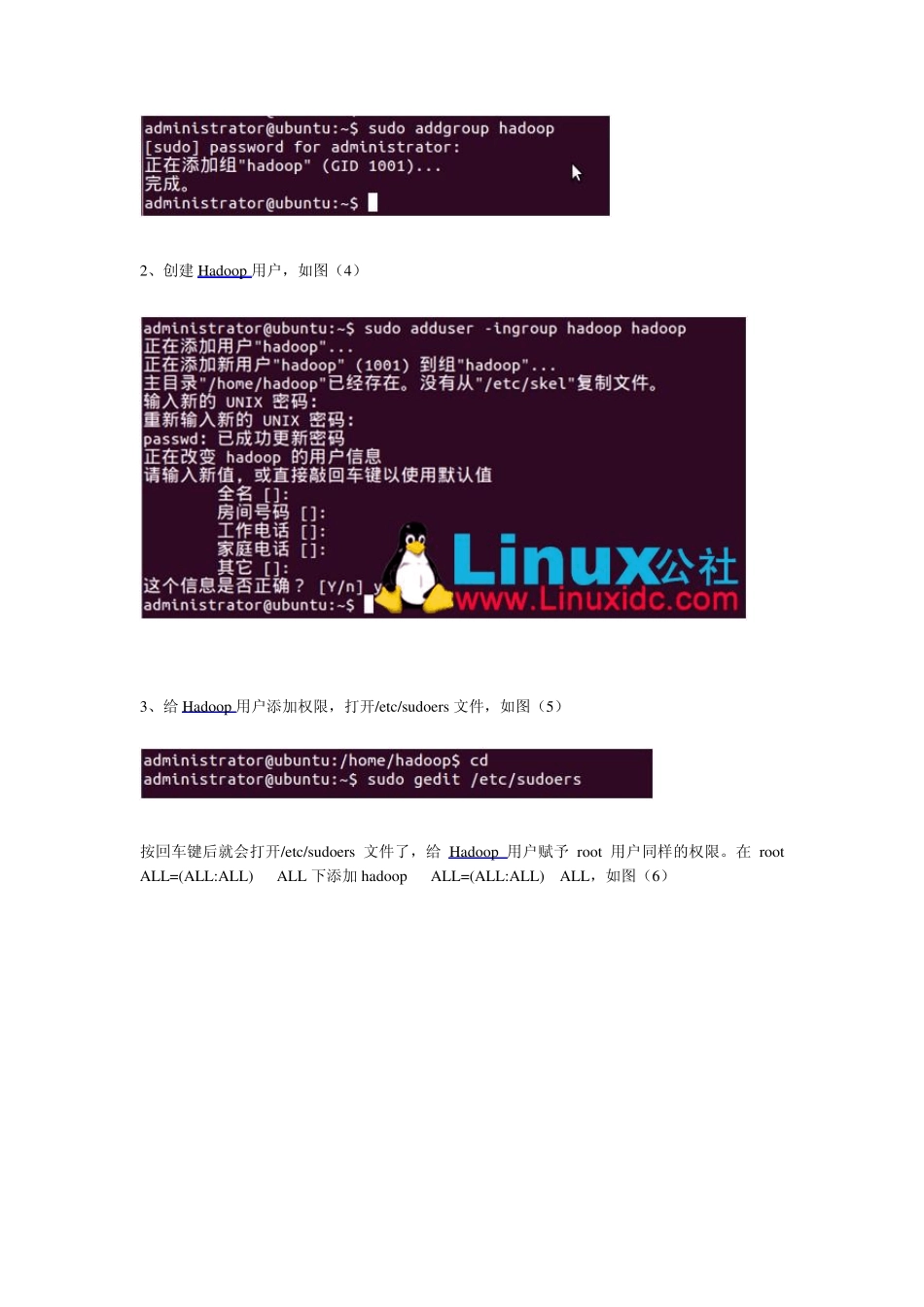
) 二、在 Ubu ntu 下创建 Hadoop 用户组和用户 这里考虑的是以后涉及到 Hadoop