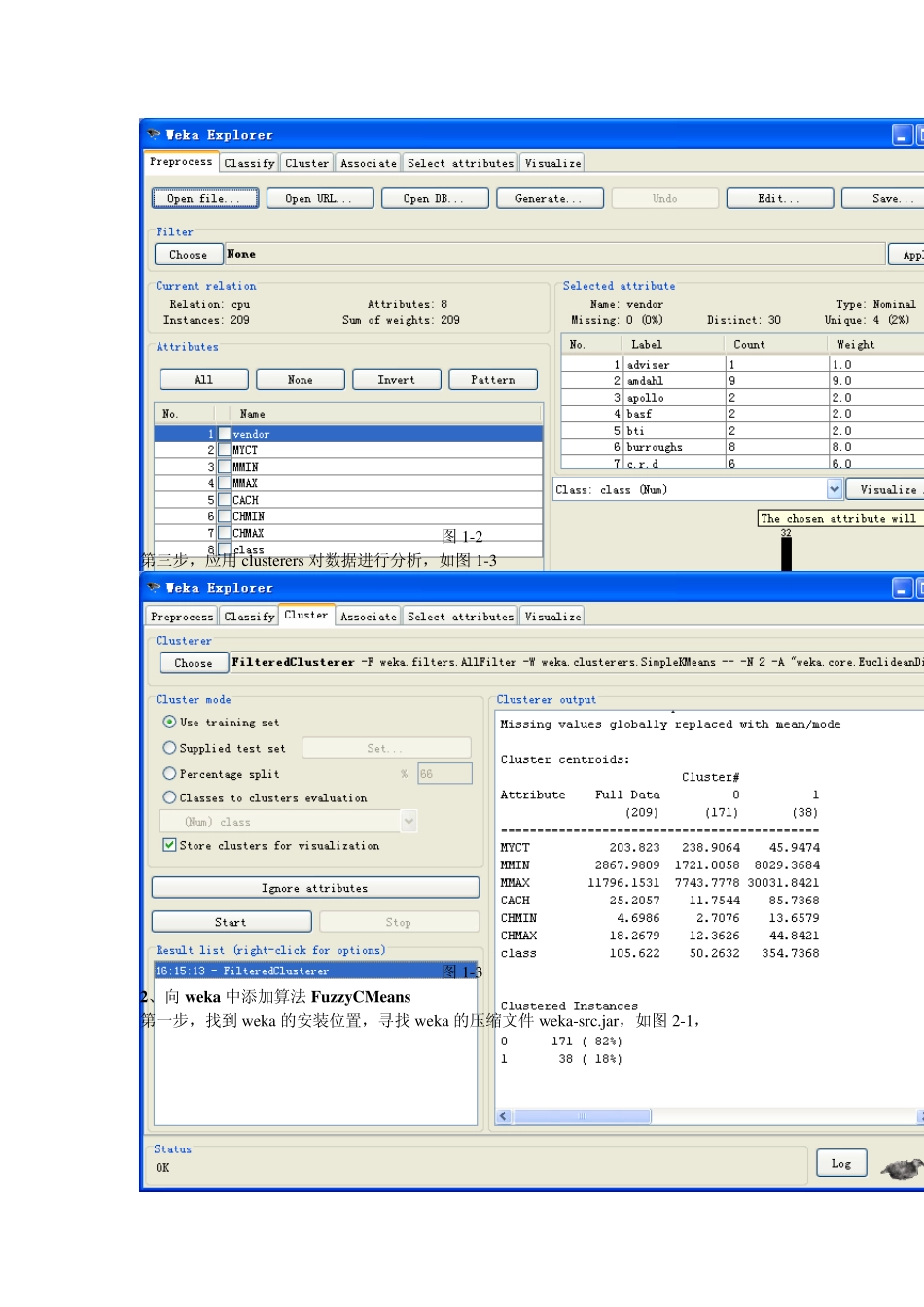
S100501179 计算机系统结构 连忠林 weka 中添加FuzzyCMeans 算法 WEKA 作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化,通过 myeclipse 平台向 weka 中添加算法接口
FuzzyCMeans 算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小
模糊 C 均值算法是普通 C 均值算法的改进,普通 C 均值算法对于数据的划分是硬性的,而 FCM 则是一种柔性的模糊划分
一、模糊 C 均值聚类 模糊 C 均值聚类(FCM),即众所周知的模糊 ISODATA,是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法
1973 年,Bezdek 提出了该算法,作为早期硬 C 均值聚类(HCM)方法的一种改进
FCM 把 n 个向量xi(i=1,2,…,n)分为c 个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小
FCM 与 HCM 的主要区别在于 FCM 用模糊划分,使得每个给定数据点用值在 0,1 间的隶属度来确定其属于各个组的程度
与引入模糊划分相适应,隶属矩阵 U 允许有取值在 0,1 间的元素
不过,加上归一化规定,一个数据集的隶属度的和总等于 1: ciijnju1,
,1,1 (6
9) 那么,FCM 的价值函数(或目标函数)就是式(6
2)的一般化形式: cinjijmijciicduJccUJ1211),
,,(, (6
10) 这里 uij 介于 0,1 间;ci 为模糊组 I 的聚类中心,dij=||ci-xj||为第 I 个聚类中心与第 j 个数据点间的欧几里德距离;且 ,1m是一个加权指数