网络爬虫是什么网络爬虫的定义:网络蜘蛛( spider ),网络机器人( robot ),这是一个程序,其会自动的通过网络抓取互联网上的网页,网络爬虫是一个自动提取网页的程序, 它为搜索引擎从 Web 上下载网页 , 是搜索引擎的重要组成部分
通用网络爬虫从一个或若干初始网页的 URL (可以称这些 URL为种子
)开始 , 获得初始网页上的URL 列表; 在抓取网页的过程中 , 不断从当前页面上抽取新的URL 放入待爬行队列 , 直到满足系统的停止条件
主题网络爬虫就是根据一定的网页分析算法过滤与主题无关的链接, 保留主题相关的链接并将其放入待抓取的URL 队列中 ; 然后根据一定的搜索策略从队列中选择下一步要抓取的网页URL, 并重复上述过程 , 直到达到系统的某一条件时停止
所有被网络爬虫抓取的网页将会被系统存储 , 进行一定的分析、 过滤, 并建立索引 , 对于主题网络爬虫来说 , 这一过程所得到的分析结果还可能对后续的抓取过程进行反馈和指导
聚焦爬虫主题爬虫 [1]并不追求高的覆盖率,而是选择性地取主题相关页面,具有资源占用低、 索引数据库更新方便、缓存页面精确的优点
但是其实现存在以下难点:如何对主题建模,如何判定页面与主题的相关性以及如何在一个爬虫系统中容纳不同的主题抓取等
主题网络爬虫根据一定的网页分析算法过滤与主题无关的链接,遵循一定的调度策略从队列中选择下一步要抓取的 URL ,同时系统存储的网页经过分析后的结果会反馈回来指导后续的抓取过程
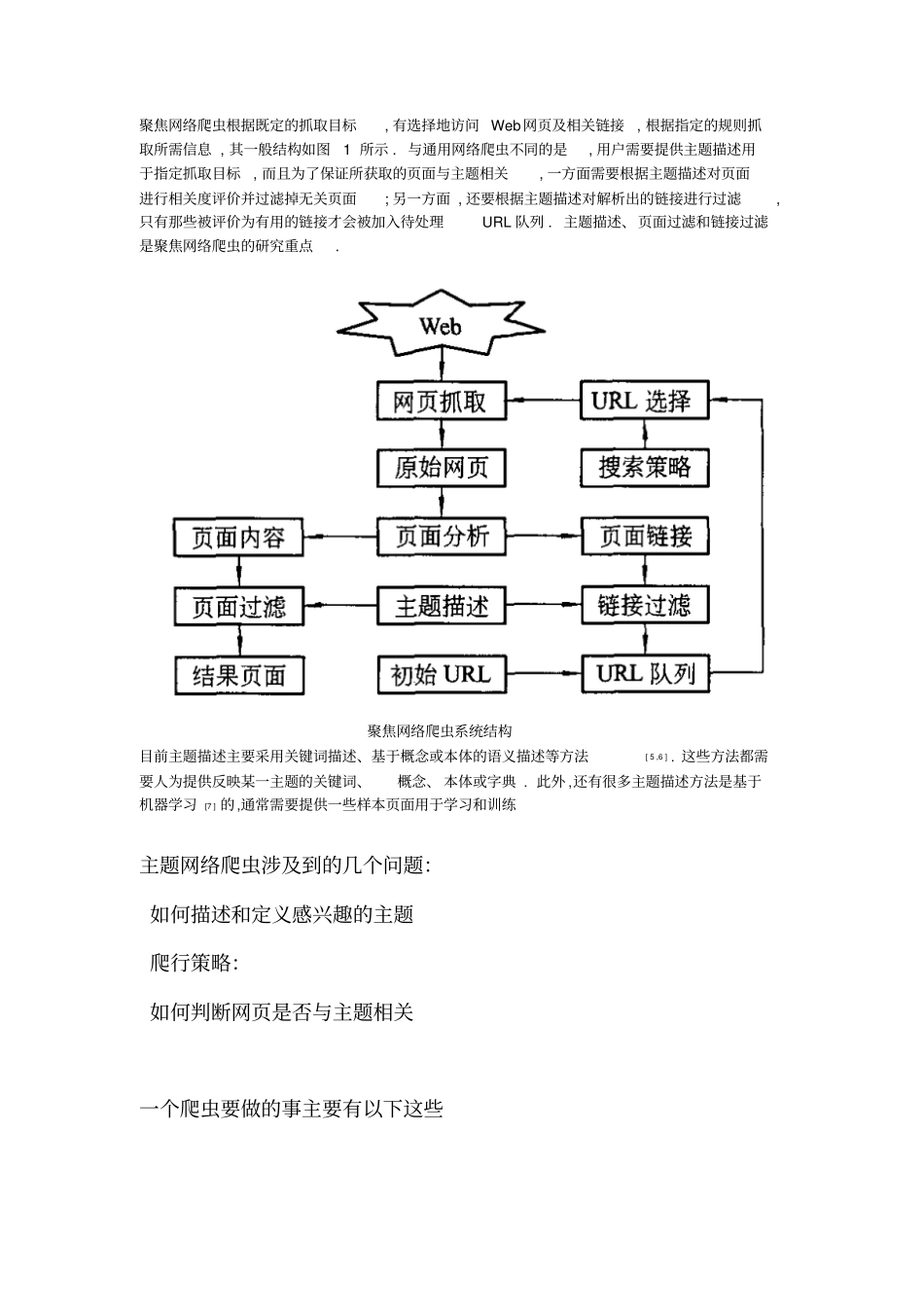
聚焦网络爬虫根据既定的抓取目标, 有选择地访问 Web 网页及相关链接, 根据指定的规则抓取所需信息 , 其一般结构如图1 所示
与通用网络爬虫不同的是, 用户需要提供主题描述用于指定抓取目标, 而且为了保证所获取的页面与主题相关, 一方面需要根据主题描述对页面进行相关度评价并过滤掉无关页面; 另一方面 ,