下载后可任意编辑具有重要用途的讨论课题
而在这些数据中,文本数据又是数量最大的一类
“文本分类是指在给定分类体系下,根据文本内容自动确定文本类别的过程”(达观数据科技联合创始人,张健)
文本分类有着广泛的应用场景,例如:新闻网站包含大量报道文章,基于文章内容,需要将这些文章按题材进行自动分类(例如自动划分成政治、经济、军事、体育、娱乐等
在电子商务网站,用户进行了交易行为后对商品进行评价分类,商家需要对用户的评价划分为正面评价和负面评价,来猎取各个商品的用户反馈统计情况
电子邮箱频繁接收到垃圾广告信息,通过文本分类技术从众多的邮件中识别垃圾邮件并过滤,提高了邮箱用户的使用效率
媒体每日有大量投稿,依靠文本分类技术能够对文章进行自动审核,标记投稿中的色情、暴力、政治、垃圾广告等违规内容
20 世纪 90 年代以前,占主导地位的文本分类方法一直是基于知识工程的方法:借助专业人员的帮助,为每个类别定义大量的推理规则,假如一篇文档能满足这些推理规则,则可以判定属于该类别
但是这种方法有明显的缺点:分类的质量依赖于规则的好坏;需要大量的专业人员进行规则的制定;不具备可推广性,不同的领域需要构建完全不同的分类系统,造成开发资源和资金资源的巨大浪费
而机器学习技术能很好地解决上述问题,以统计理论为基础,利用算法让机器具有类似人类般的自动“学习”能力——对已知的训练数据做统计分析从而获得规律,再运用规律对未知数据做预测分析
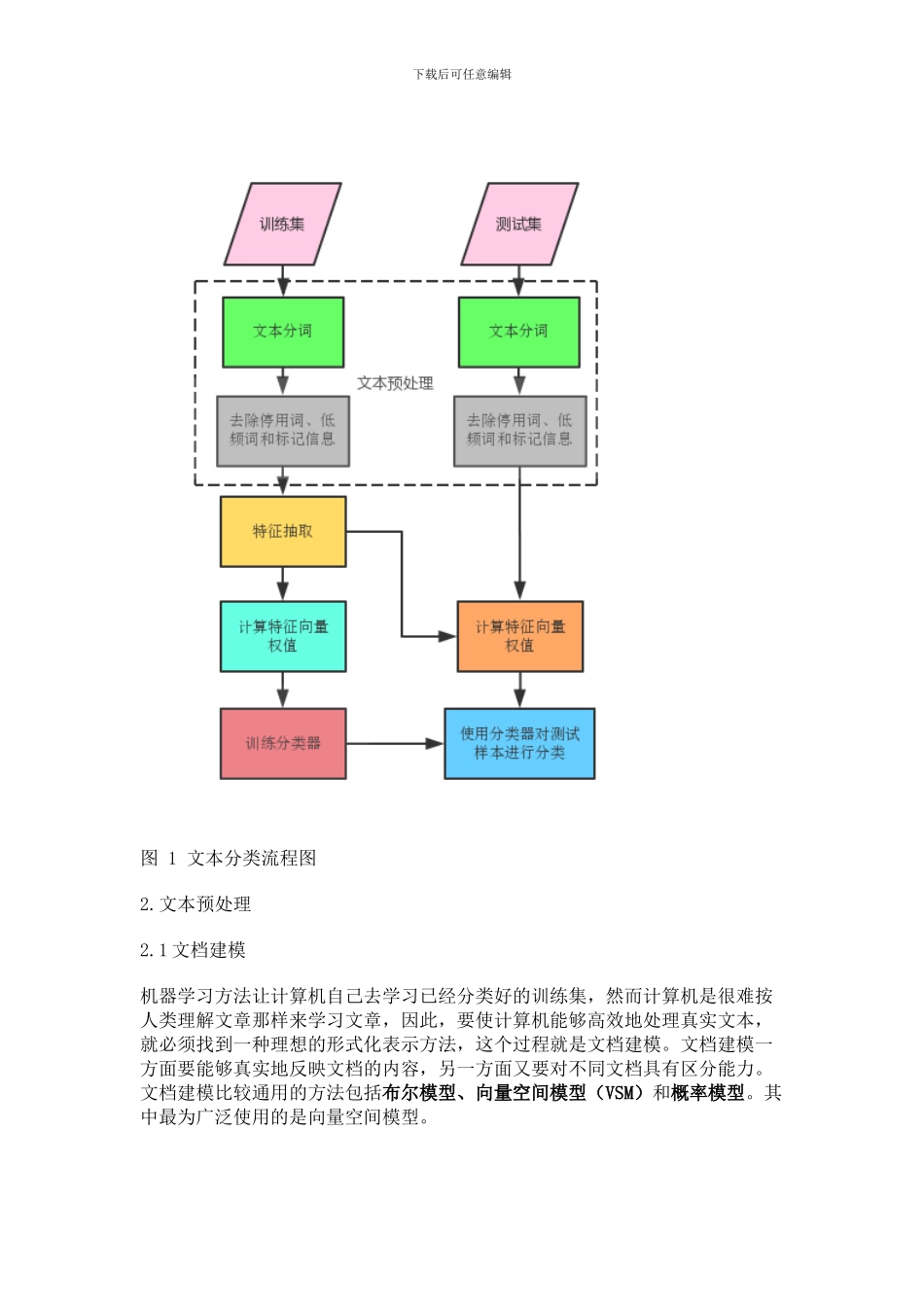
机器学习方法运用在文本分类上的基本过程就是:标注——利用人工对一批文档进行了准确分类,以作为训练集(进行机器学习的材料);训练——计算机从这些文档中挖掘出一些能够有效分类的规则,生成分类器(总结出的规则集合);分类——将生成的分类器应用在有待分类的文档集合中,猎取文档的分类结果
由于机器学习方法在文本分类领域有着良好的实际表现,已经成为了该领域的主流