精品文档---下载后可任意编辑一
分类及决策树介绍 1
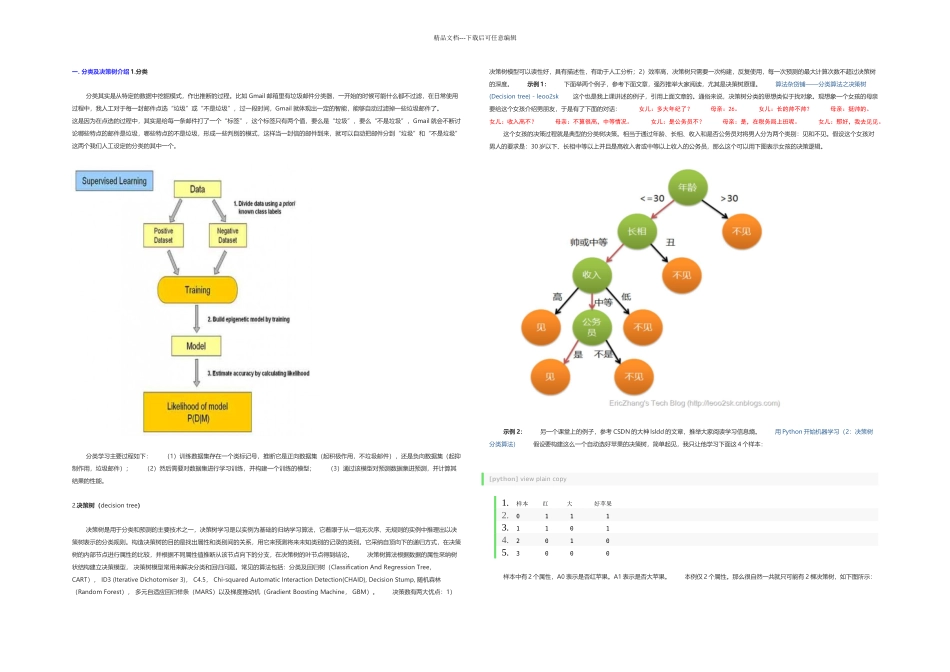
分类 分类其实是从特定的数据中挖掘模式,作出推断的过程
比如 Gmail 邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选“垃圾”或“不是垃圾”,过一段时间,Gmail 就体现出一定的智能,能够自动过滤掉一些垃圾邮件了
这是因为在点选的过程中,其实是给每一条邮件打了一个“标签”,这个标签只有两个值,要么是“垃圾”,要么“不是垃圾”,Gmail 就会不断讨论哪些特点的邮件是垃圾,哪些特点的不是垃圾,形成一些判别的模式,这样当一封信的邮件到来,就可以自动把邮件分到“垃圾”和“不是垃圾”这两个我们人工设定的分类的其中一个
分类学习主要过程如下: (1)训练数据集存在一个类标记号,推断它是正向数据集(起积极作用,不垃圾邮件),还是负向数据集(起抑制作用,垃圾邮件); (2)然后需要对数据集进行学习训练,并构建一个训练的模型; (3)通过该模型对预测数据集进预测,并计算其结果的性能
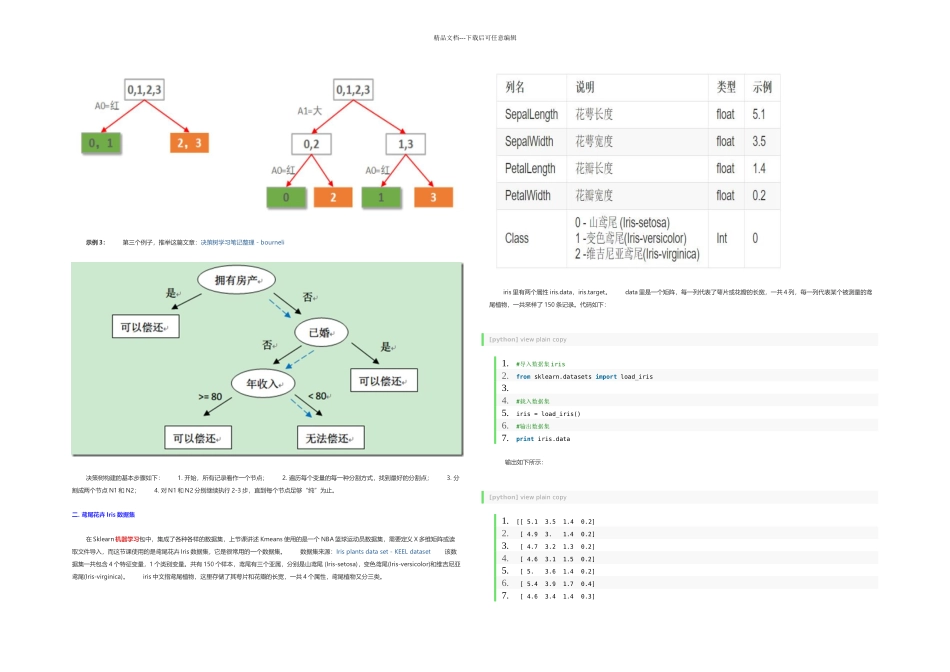
决策树(decision tree) 决策树是用于分类和预测的主要技术之一,决策树学习是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则
构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别
它采纳自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值推断从该节点向下的分支,在决策树的叶节点得到结论
决策树算法根据数据的属性采纳树状结构建立决策模型, 决策树模型常用来解决分类和回归问题
常见的算法包括:分类及回归树(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4
5, Chi-squared Autom