本文从互联网收集并整理了推荐系统的架构,其中包括一些大公司的推荐系统框架(数据流存储、计算、模型应用),可以参考这些资料,取长补短,最后根据自己的业务需求,技术选型来设计相应的框架
后续持续更新并收集
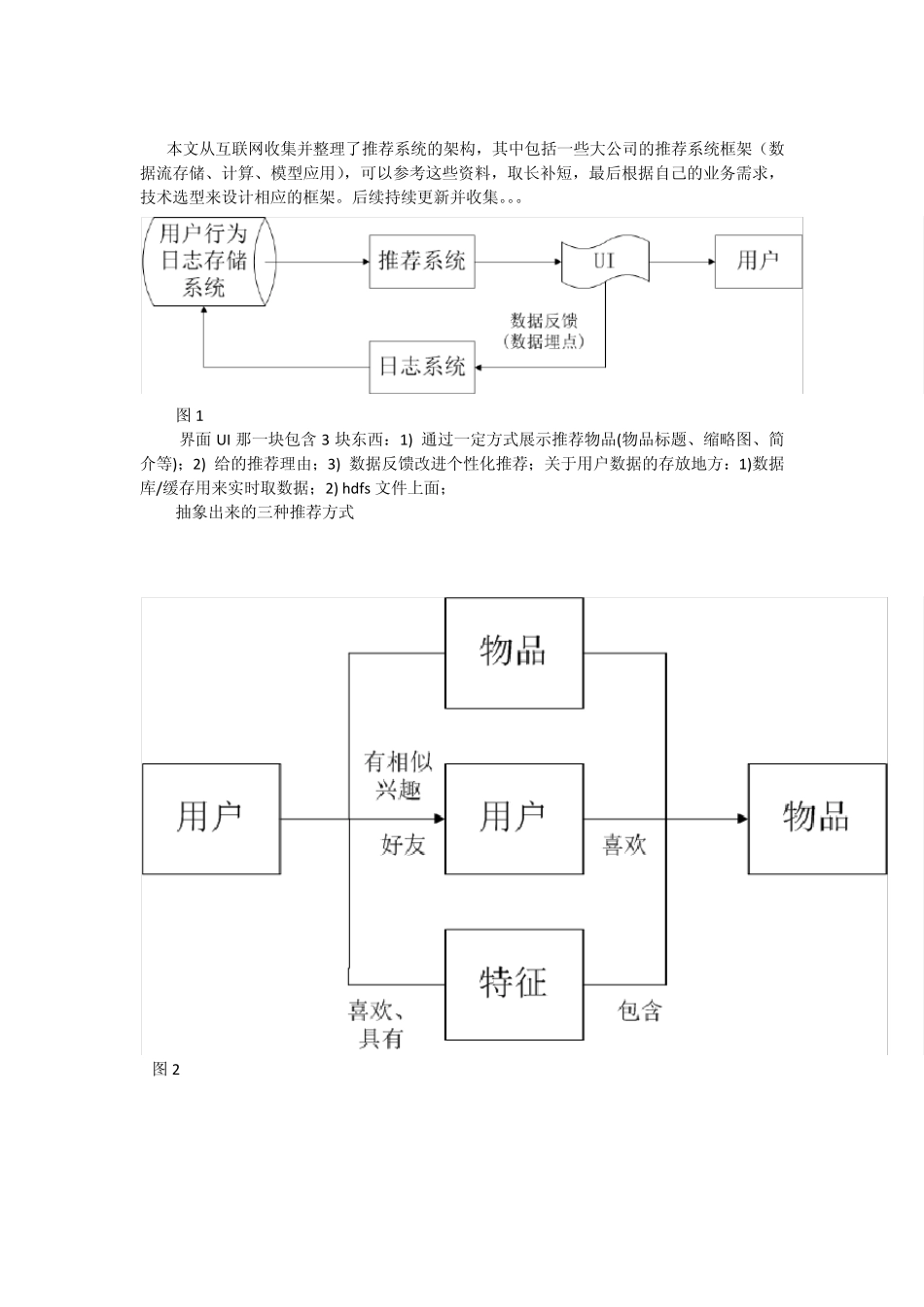
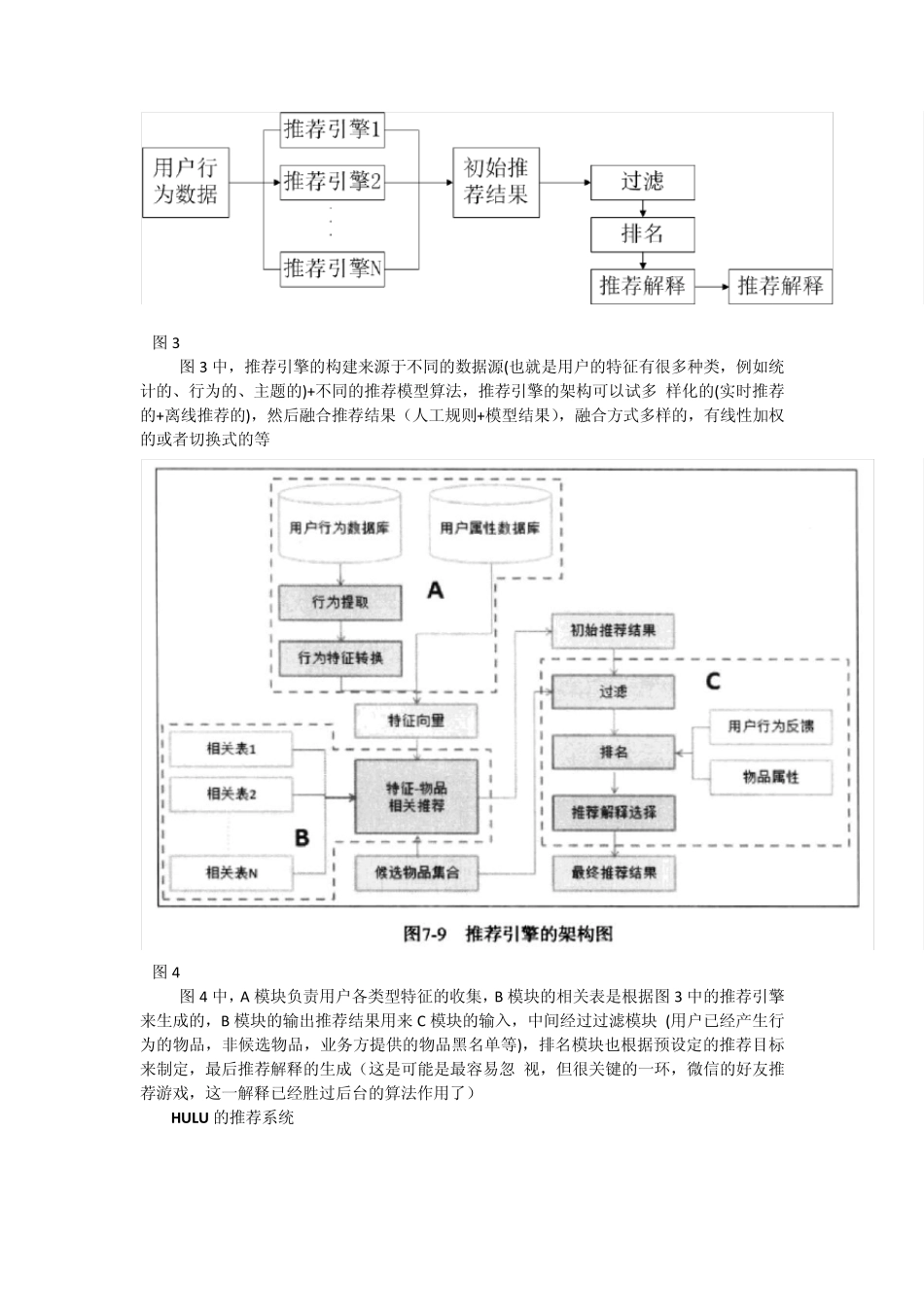
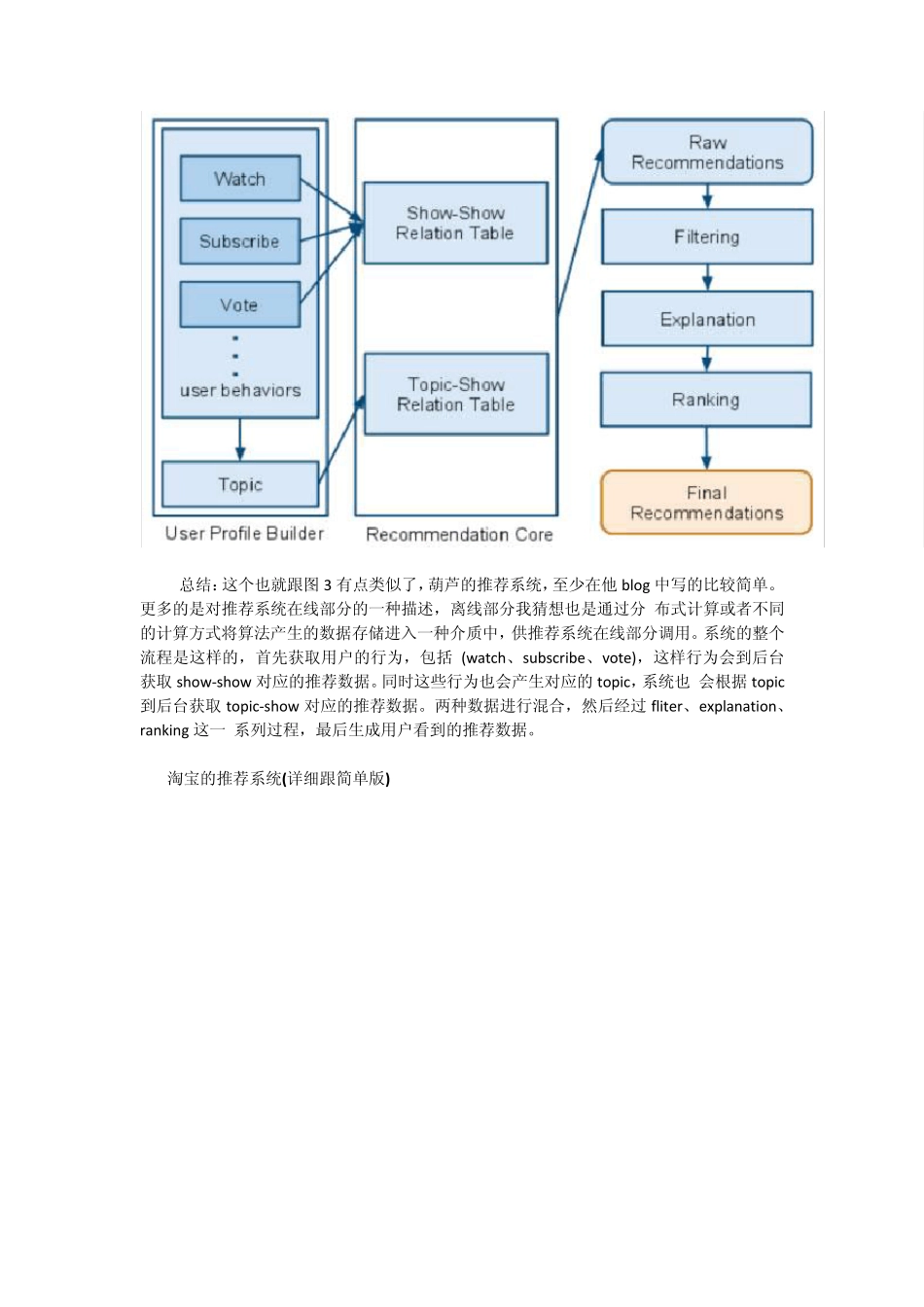
图 1 界面 UI 那一块包含 3 块东西:1) 通过一定方式展示推荐物品(物品标题、缩略图、简介等);2) 给的推荐理由;3) 数据反馈改进个性化推荐;关于用户数据的存放地方:1)数据库/缓存用来实时取数据;2) hdfs文件上面; 抽象出来的三种推荐方式 图 2 图3 图3 中,推荐引擎的构建来源于不同的数据源(也就是用户的特征有很多种类,例如统计的、行为的、主题的)+不同的推荐模型算法,推荐引擎的架构可以试多 样化的(实时推荐的+离线推荐的),然后融合推荐结果(人工规则+模型结果),融合方式多样的,有线性加权的或者切换式的等 图4 图4 中,A 模块负责用户各类型特征的收集,B 模块的相关表是根据图3 中的推荐引擎来生成的,B 模块的输出推荐结果用来C 模块的输入,中间经过过滤模块 (用户已经产生行为的物品,非候选物品,业务方提供的物品黑名单等),排名模块也根据预设定的推荐目标来制定,最后推荐解释的生成(这是可能是最容易忽 视,但很关键的一环,微信的好友推荐游戏,这一解释已经胜过后台的算法作用了) HU LU 的推荐系统 总结:这个也就跟图3 有点类似了,葫芦的推荐系统,至少在他blog 中写的比较简单
更多的是对推荐系统在线部分的一种描述,离线部分我猜想也是通过分 布式计算或者不同的计算方式将算法产生的数据存储进入一种介质中,供推荐系统在线部分调用
系统的整个流程是这样的,首先获取用户的行为,包括 (watch、subscribe、vote),这样行为会到后台获取show-show 对应的推荐数据
同时这些行为也会产生对应的topic,系统也 会根据topic到