决策树算法决策树定义首先,我们来谈谈什么是决策树
我们还是以鸢尾花为例子来说明这个问题
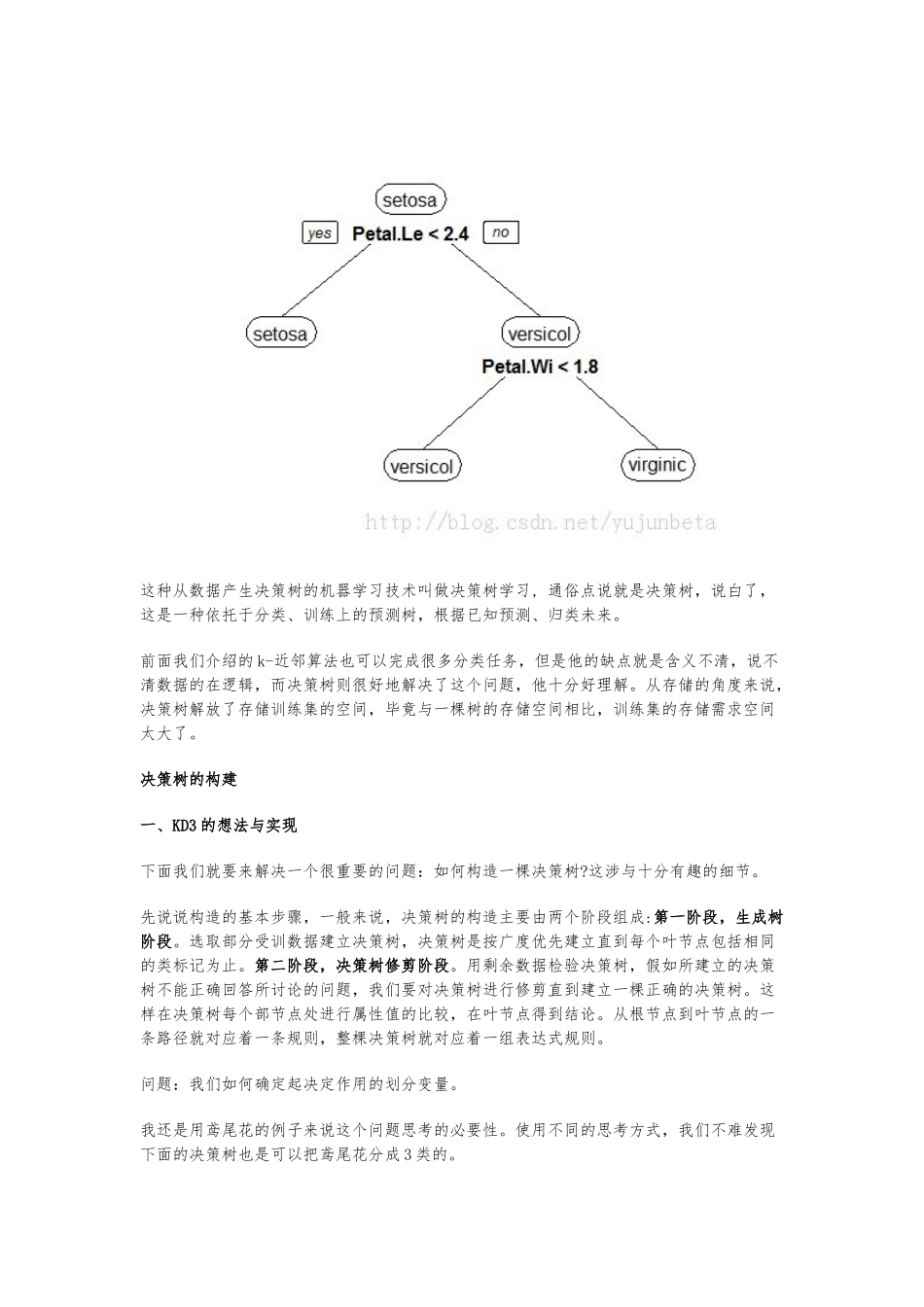
观察上图,我们判决鸢尾花的思考过程可以这么来描述:花瓣的长度小于 2
4cm 的是setosa(图中绿色的分类),长度大于 1cm 的呢
我们通过宽度来判别,宽度小于 1
8cm 的是versicolor(图中红色的分类),其余的就是 virginica(图中黑色的分类)我们用图形来形象的展示我们的思考过程便得到了这么一棵决策树:这种从数据产生决策树的机器学习技术叫做决策树学习, 通俗点说就是决策树,说白了,这是一种依托于分类、训练上的预测树,根据已知预测、归类未来
前面我们介绍的 k-近邻算法也可以完成很多分类任务,但是他的缺点就是含义不清,说不清数据的在逻辑,而决策树则很好地解决了这个问题,他十分好理解
从存储的角度来说,决策树解放了存储训练集的空间,毕竟与一棵树的存储空间相比,训练集的存储需求空间太大了
决策树的构建一、KD3 的想法与实现下面我们就要来解决一个很重要的问题:如何构造一棵决策树
这涉与十分有趣的细节
先说说构造的基本步骤,一般来说,决策树的构造主要由两个阶段组成:第一阶段,生成树阶段
选取部分受训数据建立决策树,决策树是按广度优先建立直到每个叶节点包括相同的类标记为止
第二阶段,决策树修剪阶段
用剩余数据检验决策树,假如所建立的决策树不能正确回答所讨论的问题,我们要对决策树进行修剪直到建立一棵正确的决策树
这样在决策树每个部节点处进行属性值的比较,在叶节点得到结论
从根节点到叶节点的一条路径就对应着一条规则,整棵决策树就对应着一组表达式规则
问题:我们如何确定起决定作用的划分变量
我还是用鸢尾花的例子来说这个问题思考的必要性
使用不同的思考方式,我们不难发现下面的决策树也是可以把鸢尾花分成 3 类的
为了找到决定性特征,划分出最正确结果,我们必须仔细评估每个特征