matlab 实现 apriori 算法源代码一、实验目的通过实验,加深数据挖掘中一个重要方法——关联分析的认识,其经典算法为apriori 算法,了解影响 apriori 算法性能的因素,掌握基于 apriori 算法理论的关联分析的原理和方法
二、实验内容对一数据集用 apriori 算法做关联分析,用 matlab 实现
三、方法手段关联规则挖掘的一个典型例子是购物篮分析
市场分析员要从大量的数据中发现顾客放入其购物篮中的不同商品之间的关系
假如顾客买牛奶,他也购买面包的可能性有多大 什么商品组或集合顾客多半会在一次购物时同时购买
例如,买牛奶的顾客有 80%也同时买面包,或买铁锤的顾客中有 70%的人同时也买铁钉,这就是从购物篮数据中提取的关联规则
分析结果可以帮助经理设计不同的商店布局
一种策略是:常常一块购买的商品可以放近一些,以便进一步刺激这些商品一起销售,例如,假如顾客购买计算机又倾向于同时购买财务软件,那么将硬件摆放离软件陈列近一点,可能有助于增加两者的销售
另一种策略是:将硬件和软件放在商店的两端,可能诱发购买这些商品的顾客一路选择其他商品
关 联 规 则 是 描 述 数 据 库 中 数 据 项 之 间 存 在 的 潜 在 关 系 的 规 则 , 形 式 为,其中,是数据库中的数据项
数据项之间的关联规则即根据一个事务中某些项的出现,可推导出另一些项在同一事务中也出现
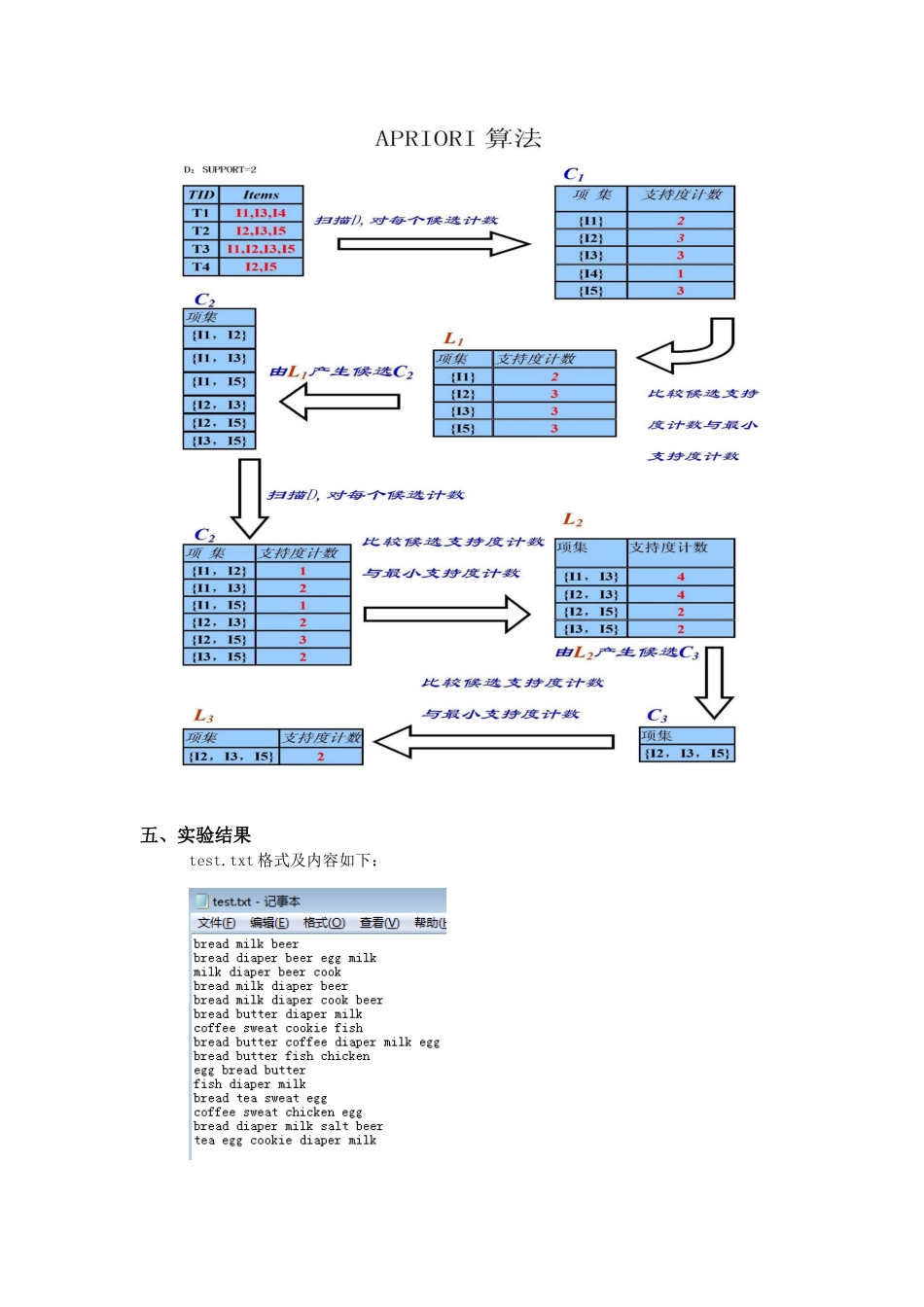
四、Apriori 算法1
算法描述Apriori 算法的第一步是简单统计所有含一个元素的项集出现的频率,来决定最大的一维项目集
在第 k 步,分两个阶段,首先用一函数 sc_candidate(候选),通过第(k-1)步中生成的最大项目集 Lk-1来生成侯选项目集 Ck
然后搜索数据库计算侯选项目集 Ck的支持度
为了更快速地计算 Ck中项目的支持度, 文中使用函数 count_sup