网页文章正文采集方法,以及微信文章采集为例当我们想要将今日头条上的新闻、搜狗微信上的文章正文内容保存下来的时候,怎么办
一篇篇复制粘贴
选择一款通用的网页数据采集器,将会使工作简单很多
八爪鱼是一款通用的网页数据采集器,可采集互联网上的公开数据
用户可以设置从哪个网站爬取数据,爬取那些数据,爬取什么范围的数据,什么时候去爬取数据,爬取的数据如何保存等等
言归正传,本文将以搜狗微信的文章正文采集为例,讲解使用八爪鱼采集网页文章正文的方法
文章正文采集,主要有两大类情况:一、采集文章正文中的文本,不含图片;二、采集文章正文中的文本和图片URL
示例网站:http://weixin
com/使用功能点:Xpathhttp://www
bazhuayu
com/search
query=XPath判断条件http://www
bazhuayu
com/tutorialdetail-1/judge
html分页列表信息采集http://www
bazhuayu
com/tutorial/fylb-70
t=1AJAX滚动教程http://www
bazhuayu
com/tutorialdetail-1/ajgd_7
htmlAJAX点击和翻页http://www
bazhuayu
com/tutorialdetail-1/ajaxdjfy_7
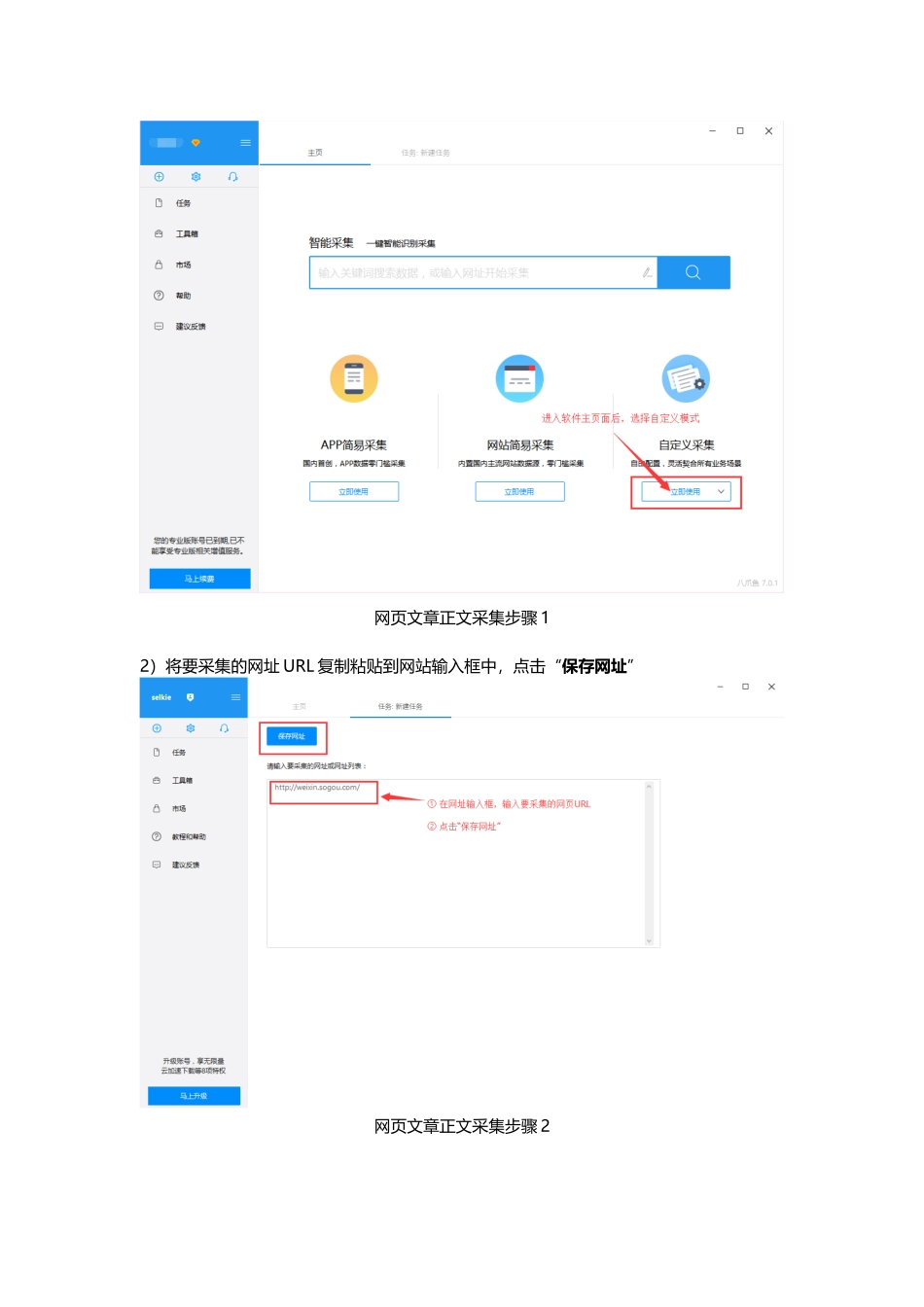
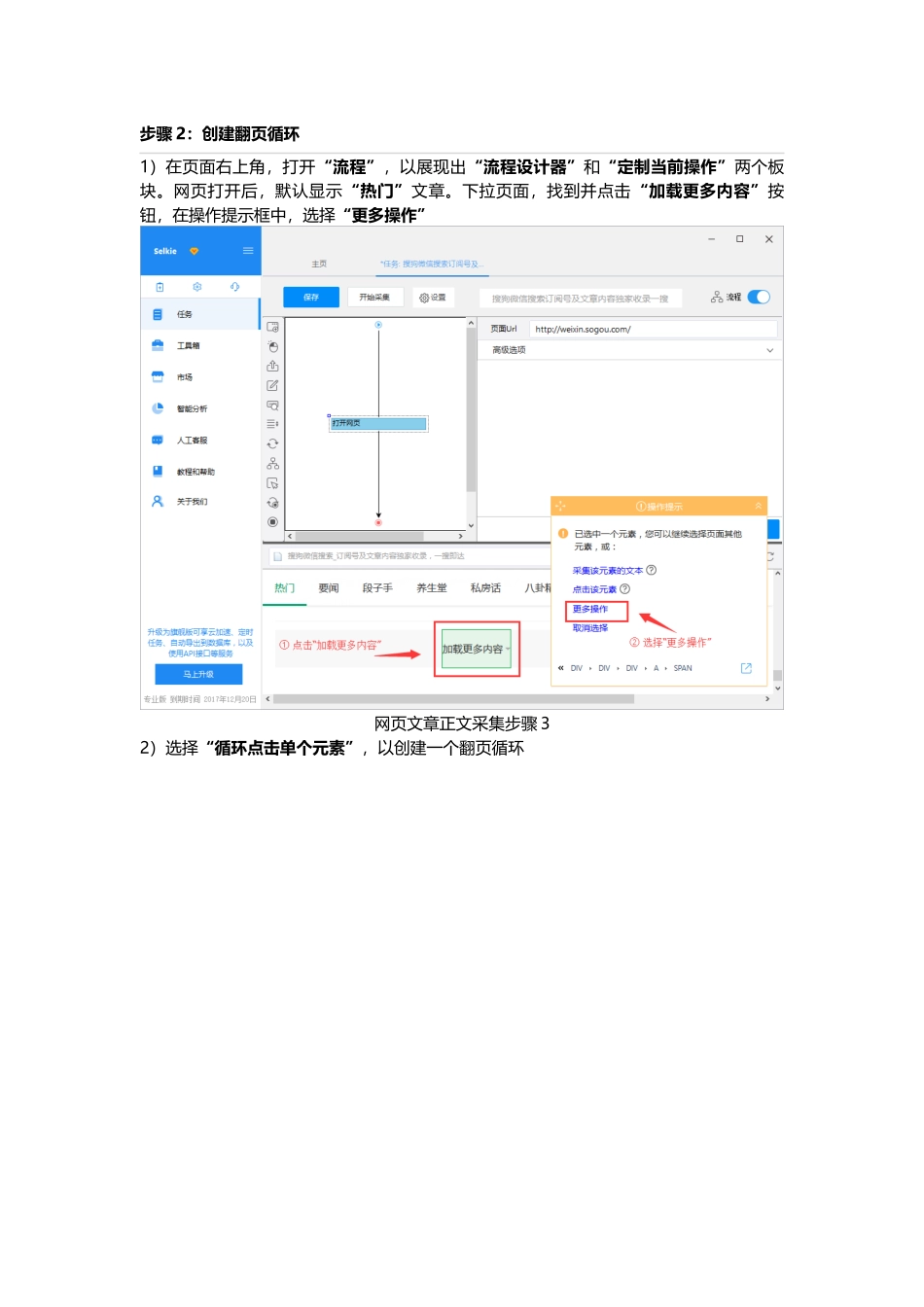
html一、采集文章正文中的文本,不含图片具体步骤:步骤1:创建采集任务1)进入主界面,选择“自定义模式”网页文章正文采集步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”网页文章正文采集步骤2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块
网页打开后,默认显示“热门”文章
下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”