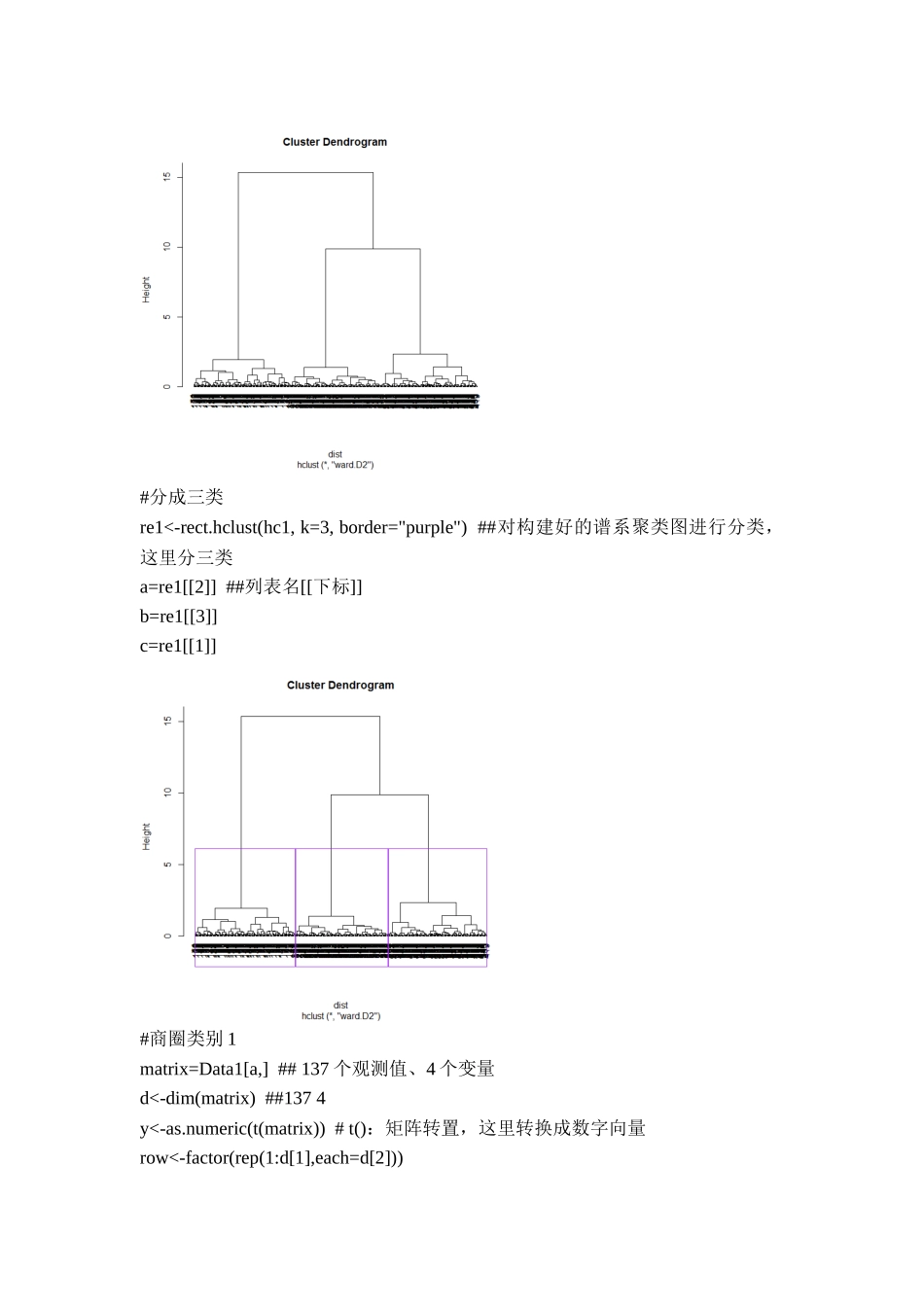
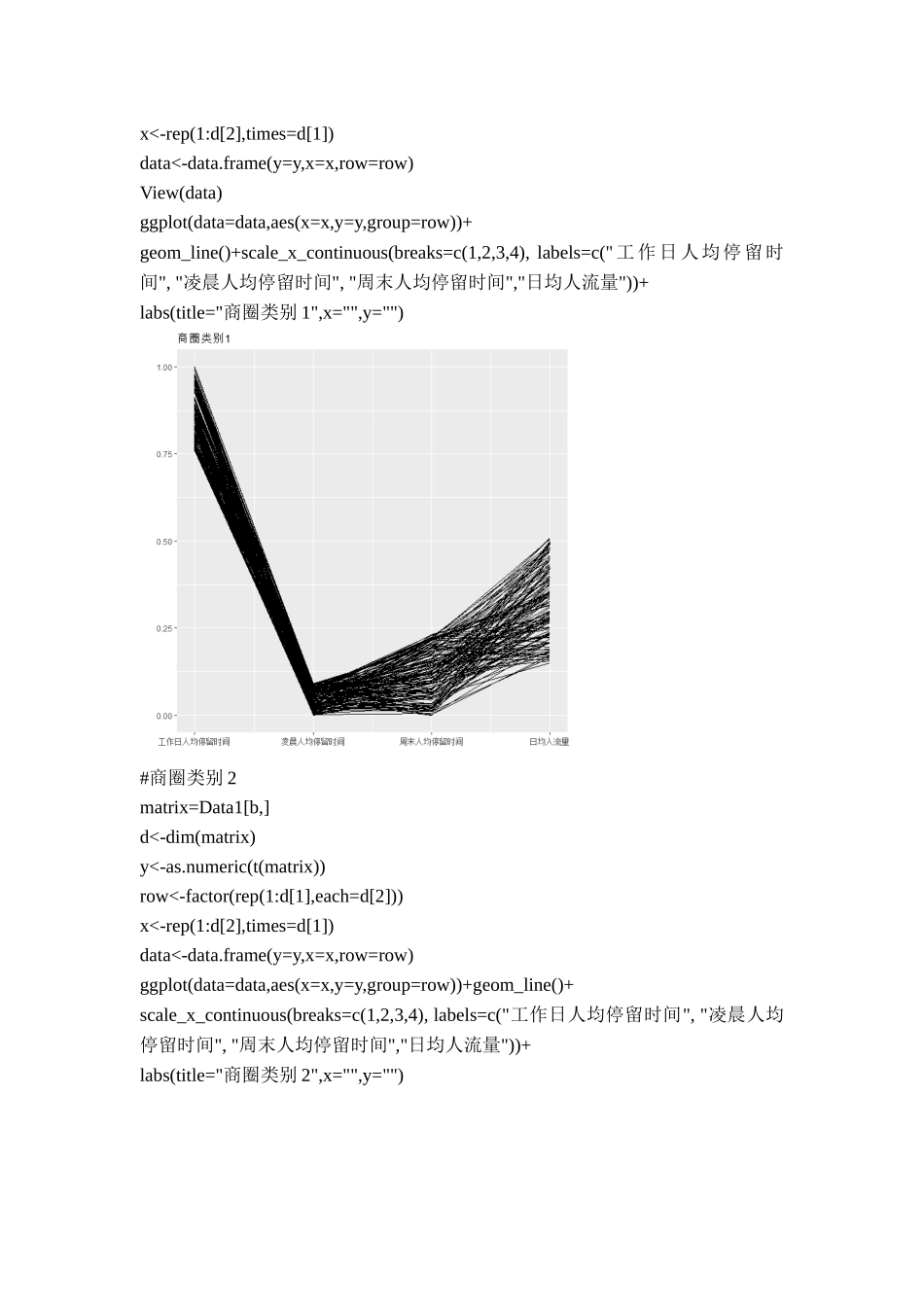
基于基站定位数据的商圈分析上机报告1数据读取及其标准化setwd("E:/数据处理")Data=read.csv("./business_circle.csv",header=T,encoding='utf-8')colnames(Data)=c("number","x1","x2","x3","x4")attach(Data)y1=(x1-min(x1))/(max(x1)-min(x1))y2=(x2-min(x2))/(max(x2)-min(x2))y3=(x3-min(x3))/(max(x3)-min(x3))y4=(x4-min(x4))/(max(x4)-min(x4))standardized=data.frame(Data[,1],y1,y2,y3,y4)write.csv(standardized,"./standardizedData.csv",row.names=TRUE)2模型构建2.1层次聚类library(ggplot2)Data=read.csv("./standardizedData.csv",header=F)Data1=data.frame(y1,y2,y3,y4)attach(Data1)dist=dist(Data1,method='euclidean')hc1<-hclust(dist,"ward.D2")plot(hc1)plot(hc1,hang=-1)#分成三类re1<-rect.hclust(hc1,k=3,border="purple")##对构建好的谱系聚类图进行分类,这里分三类a=re1[[2]]##列表名[[下标]]b=re1[[3]]c=re1[[1]]#商圈类别1matrix=Data1[a,]##137个观测值、4个变量d<-dim(matrix)##1374y<-as.numeric(t(matrix))#t():矩阵转置,这里转换成数字向量row<-factor(rep(1:d[1],each=d[2]))x<-rep(1:d[2],times=d[1])data<-data.frame(y=y,x=x,row=row)View(data)ggplot(data=data,aes(x=x,y=y,group=row))+geom_line()+scale_x_continuous(breaks=c(1,2,3,4),labels=c("工作日人均停留时间","凌晨人均停留时间","周末人均停留时间","日均人流量"))+labs(title="商圈类别1",x="",y="")#商圈类别2matrix=Data1[b,]d<-dim(matrix)y<-as.numeric(t(matrix))row<-factor(rep(1:d[1],each=d[2]))x<-rep(1:d[2],times=d[1])data<-data.frame(y=y,x=x,row=row)ggplot(data=data,aes(x=x,y=y,group=row))+geom_line()+scale_x_continuous(breaks=c(1,2,3,4),labels=c("工作日人均停留时间","凌晨人均停留时间","周末人均停留时间","日均人流量"))+labs(title="商圈类别2",x="",y="")#商圈类别3matrix=Data1[c,]d<-dim(matrix)##1484y<-as.numeric(t(matrix))row<-factor(rep(1:d[1],each=d[2]))x<-rep(1:d[2],times=d[1])data<-data.frame(y=y,x=x,row=row)ggplot(data=data,aes(x=x,y=y,group=row))+geom_line()+scale_x_continuous(breaks=c(1,2,3,4),labels=c("工作日人均停留时间","凌晨人均停留时间","周末人均停留时间","日均人流量"))+labs(title="商圈类别3",x="",y="")2.2K-means聚类setwd("E:/数据处理")Data=read.csv("./business_circle.csv",header=T,encoding='utf-8')km=kmeans(Data,center=3)print(km)#数据分组aaa=data.frame(Data,km$cluster)Data1=Data[which(aaa$km.cluster==1),]Data2=Data[which(aaa$km.cluster==2),]Data3=Data[which(aaa$km.cluster==3),]#商圈1的概率密度函数图par(mfrow=c(2,2))##公共参数列表par#设置布局plot(density(Data1[,1]),col="red",main="工作日人均停留时间")plot(density(Data1[,2]),col="red",main="凌晨人均停留时间")plot(density(Data1[,3]),col="red",main="周末人均停留时间")plot(density(Data1[,4]),col="red",main="日均人流量")#商圈2的概率密度函数图par(mfrow=c(2,2))plot(density(Data2[,1]),col="purple",main="工作日人均停留时间")plot(density(Data2[,2]),col="purple",main="凌晨人均停留时间")plot(density(Data2[,3]),col="purple",main="周末人均停留时间")plot(density(Data2[,4]),col="purple",main="日均人流量")#商圈3的概率密度函数图par(mfrow=c(2,2))plot(density(Data3[,1]),col="blue",main="工作日人均停留时间")plot(density(Data3[,2]),col="blue",main="凌晨人均停留时间")plot(density(Data3[,3]),col="blue",main="周末人均停留时间")plot(density(Data3[,4]),col="blue",main="日均人流量")3总结3.1数据标准化的方法及使用离差标准化原因1.数据标准化方法数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行...