基于数加分析政府工作报告本文章来自于阿里云云栖社区摘要:摘要:3月5日,第十二届全国人民代表大会第五次会议在北京人民大会堂开幕,两会期间的“部长通道”是每年两会的一个亮点,李克强总理多次强调要让部长们当“第一新闻发言人”,积极回应舆论关切,给社会各界一个稳定预期
摘要:3月5日,第十二届全国人民代表大会第五次会议在北京人民大会堂开幕,两会期间的“部长通道”是每年两会的一个亮点,李克强总理多次强调要让部长们当“第一新闻发言人”,积极回应舆论关切,给社会各界一个稳定预期
笔者从新浪、搜狐、网易等各大门户网站上爬取部长答记者问的相关新闻数据导入到阿里数加平台,基于阿里数加算法平台与Maxcomputer,采用分词、TFIDF、LDA、聚类等文本分析算法,分析两会部长通道都回答了哪些热点问题,都有哪些主题
另外分析了40年《政府工作报告》中关注焦点的变化,以及在2017年的《政府工作报告》又出现了哪些新词汇与热词
一、文本分析架构文本分析架构图1
数据源:主要为互联网各大网站上的文本数据;2
数据采集:采用爬虫技术,获取网站的文本数据;3
数据同步至阿里云:使用DataX工具将文本数据导入到在ODPS建立的表中;4
流程计算:阿里云建立算法分析流程;5
分析结果:对计算出的词频以及主题存储于表;6
数据可视化展示:从数据库中读取结果数据进行可视化展示
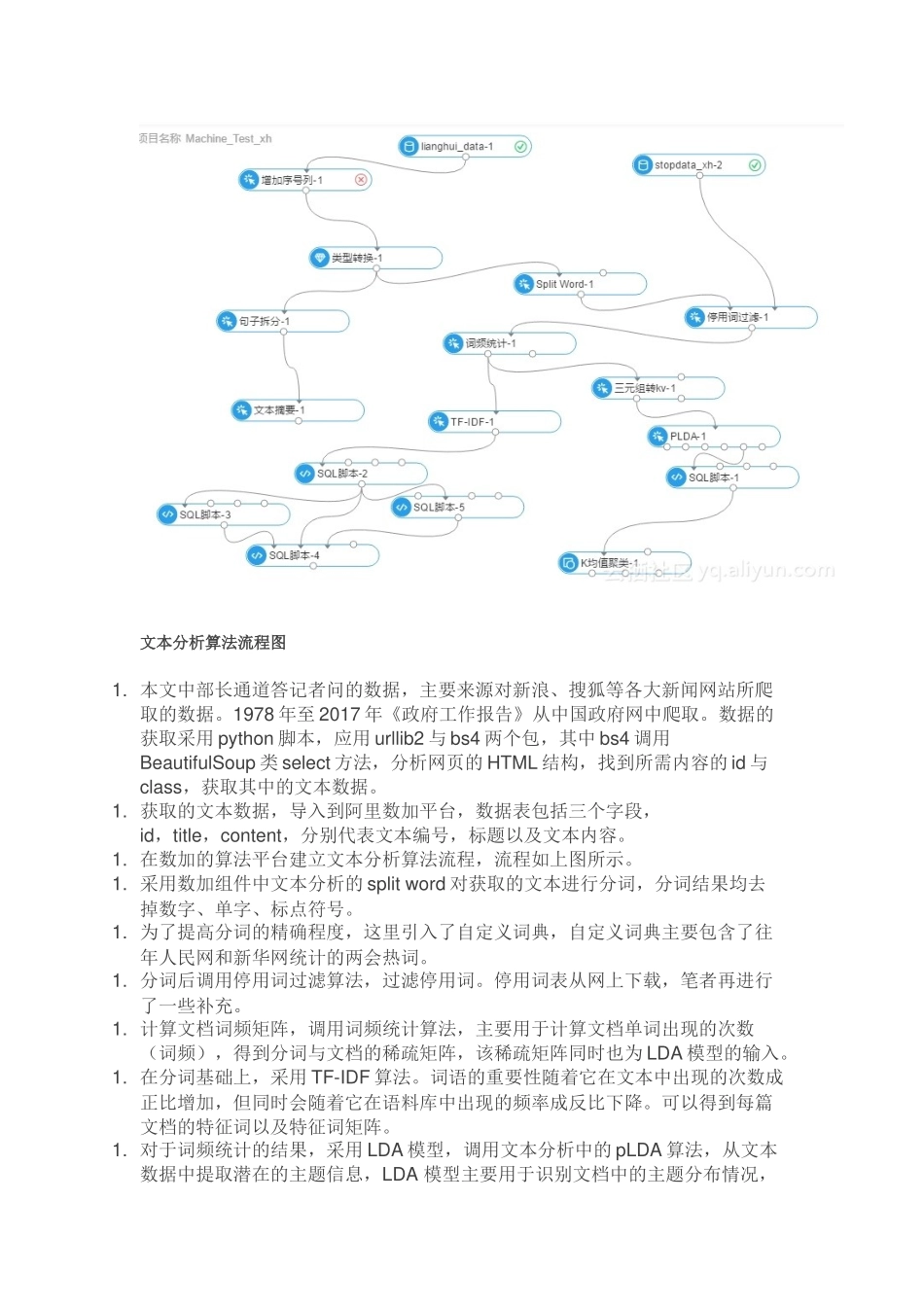
二、分析方法文本分析算法流程图1
本文中部长通道答记者问的数据,主要来源对新浪、搜狐等各大新闻网站所爬取的数据
1978年至2017年《政府工作报告》从中国政府网中爬取
数据的获取采用python脚本,应用urllib2与bs4两个包,其中bs4调用BeautifulSoup类select方法,分析网页的HTML结构,找到所需内容的id与class,获取其中的文本数据
获取的文本数据,导入到阿里数加平台,数据表包括三个字段,id,