Uniprot蛋白数据库之前,世界上最广泛使用的蛋白数据库为瑞士的SWISS-PROT计划建立的数据库,NHGRI的项目主任PeterGood介绍说
但由于编辑详细蛋白结构数据库时间紧迫,再加上资金短缺,SWISS-PROT无法跟上基因组学飞速前进的步伐,Good说
这种形势导致了TrEMBL的产生,这是计算机注释的SWISS-PROT分支数据库,目的是暂时储存日益增多的蛋白质结构信息
另外,美国的蛋白信息资源(ProteinInformationResource,PIR)也独立编辑其自己的数据库
后来,这三个计划的领导人将展开合作,将三大数据库合并为一个
联合起来的力量将“减少重复工作,由此也可以节省不必要的费用
”SWISS-PROT的领导人、英国剑桥欧洲生物信息研究院的RolfApweiler说道
,UniProt将是SWISS-PROT、TrEMBL和PIR三大数据库的最佳整合一个集中化的数据库十分重要,密歇根大学的肿瘤学家SamirHanash对此表示同意
他同时也是人类蛋白组组织(HumanProteomeOrganisation)的主席
然而,Hanash提醒说,UniProt只是一个开始,还需要建立其它的数据库来储存有关蛋白质何时何处在机体中活动的信息,他说
(2002年)这句话不仅代表了Uniport数据库,也是代表了整个生物信息学,科研本就是站在巨人的肩膀上发展的,那么这个肩膀也得与时俱进了
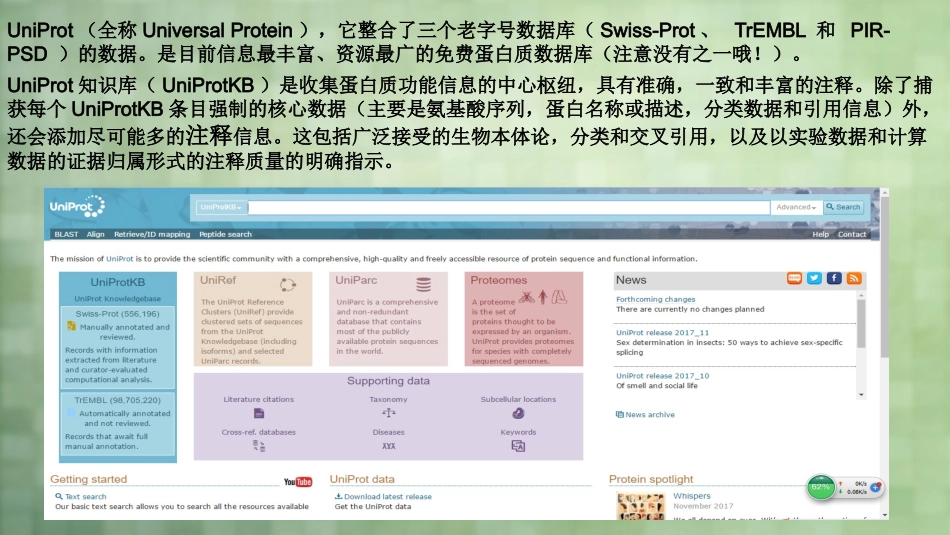
Uniport的前世今生UniProt(全称UniversalProtein),它整合了三个老字号数据库(Swiss-Prot、TrEMBL和PIR-PSD)的数据
是目前信息最丰富、资源最广的免费蛋白质数据库(注意没有之一哦
UniProt知识库(UniProtKB)是收集蛋白质功能信息的中心枢纽,具有准确,一致和丰富的注释
除了捕获每个UniProtKB条目