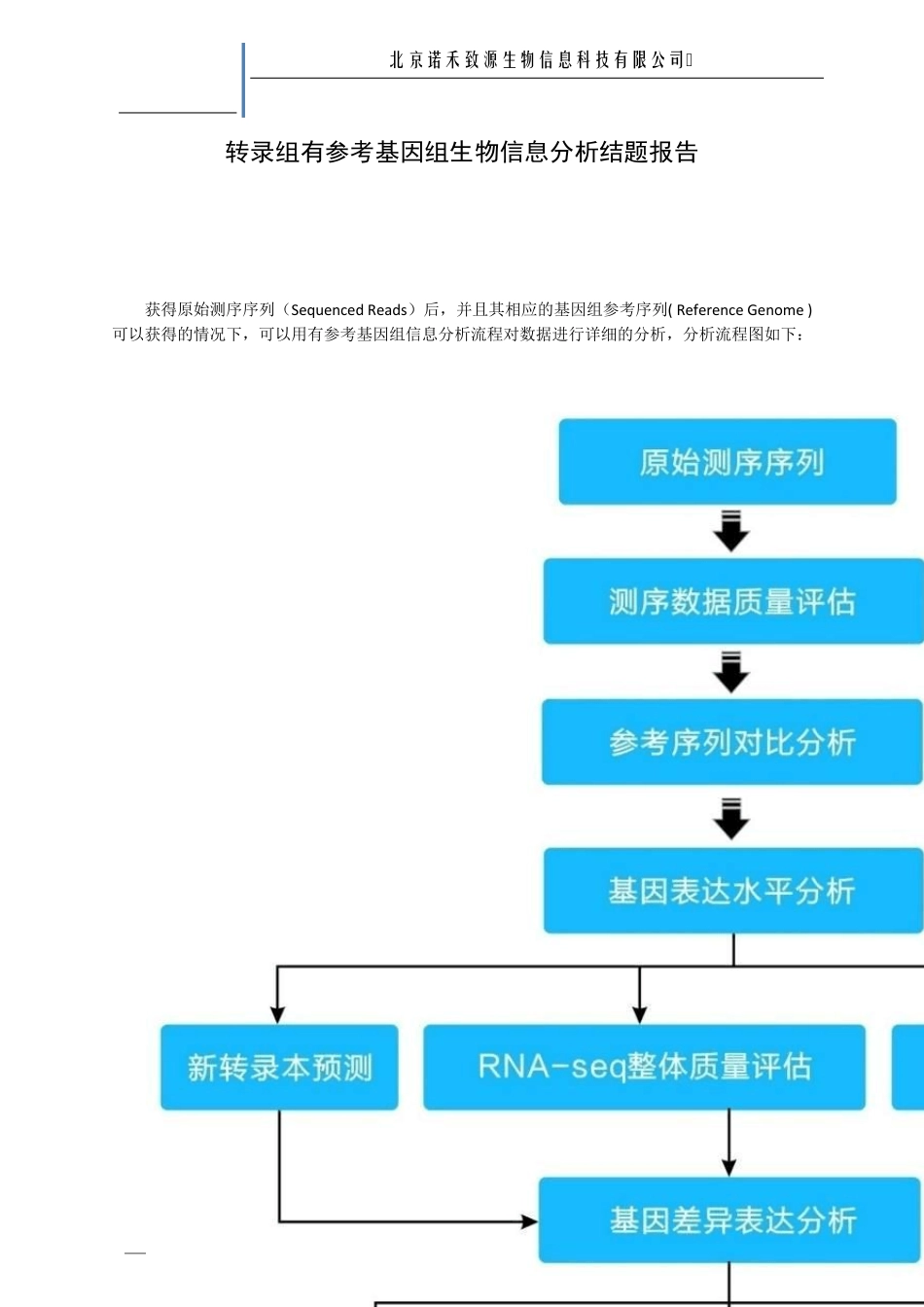
北京诺禾致源生物信息科技有限公司 1 转录组有参考基因组生物信息分析结题报告 获得原始测序序列(Sequenced Reads)后,并且其相应的基因组参考序列( Reference Genome )可以获得的情况下,可以用有参考基因组信息分析流程对数据进行详细的分析,分析流程图如下: 北京诺禾致源生物信息科技有限公司 2 1
原始序列数据 高通量测序(如Illunima HiSeqTM2000/ Miseq 等测序平台)测序得到的原始图像数据文件经碱基识别(Base Calling)分析转化为原始测序序列(Sequenced Reads),我们称之为Raw Data 或Raw Reads,结果以FASTQ(简称为fq)文件格式存储,其中包含测序序列(reads)的序列信息以及其对应的测序质量信息
测序样品中真实数据随机截取结果如下: @HWI-ST1106:227:D14F6ACXX:1:1101:1202:2188 1:N:0:GCCAAT CGGATGATCTTCTTAATCTCTCCTTGCATAGTTATGAAACAGTCCGTGGACTTGCTGGAAAATCTCTCTTGAAGATGATGAAGAGATGGCCCTCTACAAT + CCCFFFDFFHHHHJJJJJIJIGGGIGICIGIIJEIIJIIJJI@DHEDHECFGGAHGGJGHIICGEEIEHGGGIECEEHH@HE>C@EBBE@CCDDCCCDDC @HWI-ST1106:227:D14F6ACXX:1:1101:1237:2217 1:N:0:GCCAAT GAAGGTGAGTCTGAGGAGGCCAAGGAGGGAATGTTTGTGAAAGGATATGTCTACTAAGATATTAGAAAGTATGTACTACTACTACTACTACATGTTTTCA + @@@FDAD