1 2 3 4 5 Mplu s 6
1 使用示例 6 7 8 9 1 0 11 Mplu s 结构方程模型步骤(入门) 1 数据格式转换 因为Mplu s 只能打开ASCII 格式的文件(
tx t 文件),所以常规的SPSS 数据库的数据不能被读取,所以数据分析之前先要将sav 格式另存为dat 格式
另存为选项里有两类dat 格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定 ASCII 格式”
这两类并没有明显特异的使用条件
1 2 选择某种dat 格式后,“将变量名写入表格”这一项不要勾选
一般将该数据文件和 mplu s 语句文件放在一个文件夹
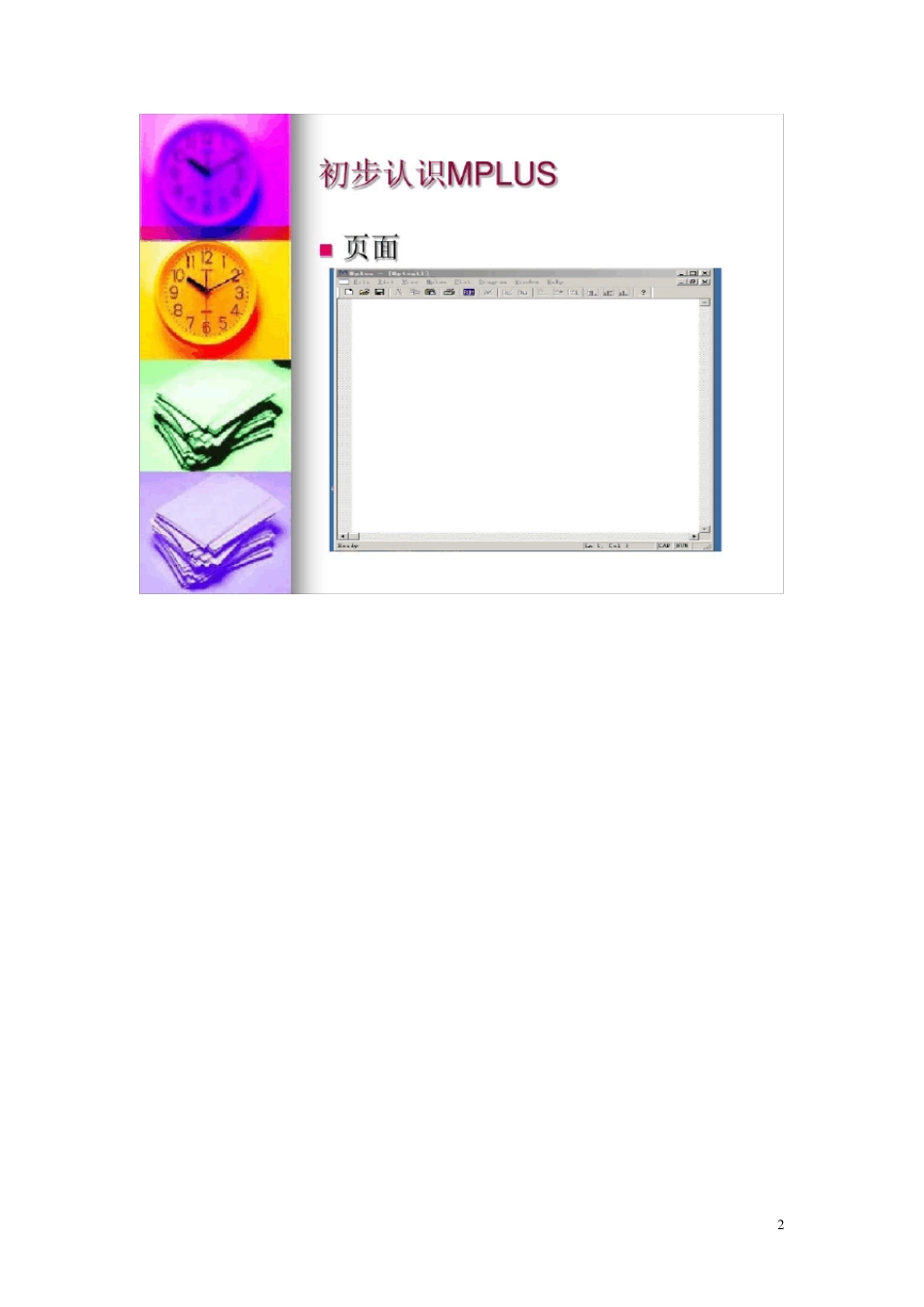
13 2 打开mplus 程序,建立新文件,即点击“new”
当然,新打开Mplus 程序也会默认这个界面
3 编辑命令
这是 Mplus 分析数据最核心的步骤 3
1 首先我们可以给该分析起个名字(该步骤可有可无),例如: TITLE: example 3
2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个 DAT 文件
命令为: DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库
dat; 这里面需要注意的是: DATA: FILE IS (或者 DATA: FILE=)是固定句式,是必要的
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库
dat”这是 DAT 文件的保存路径
一般情况下,如果 mplu s 语句文件和 dat 文件在同一个文件夹中,只需要 DATA: 14 FILE IS 数据库
dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT 文件的保存路径写全,这样肯定是没错的
另外,一个命令结束后,必须必须加上“;”即英文格