实 验 报 告 课程名称: 大数据技术实践 实验项目: 大数据平台 实验仪器: PC 机 学 院: 计算机学院 专 业: 计算机科学与技术 班级姓名: * 学 号: * 日 期: 2019-5-9 指导教师: * 成 绩: 一
实验目的 1
熟练掌握大数据计算平台相关系统的安装部署 2
理解大数据MapReduce 计算模型,并掌握MapReduce 程序开发 3
掌握Hive 的查询方法 4
掌握Spark 的基本操作 二
实验内容 1
Hadoop 完全分布模式安装 2
Hadoop 开发插件安装 3
MapReduce 代码实现 4
Hive 安装部署 5
Hive 查询 6
Spark Standalone 模式安装 7
Spark Shell 操作 三
实验过程 Hadoop 开发插件安装 实验步骤: 1
Eclipse 开发工具以及Hadoop 默认已经安装完毕,安装在/apps/目录下
在Linux 本地创建/data/hadoop3目录,用于存放所需文件
切换目录到/data/hadoop3目录下,并使用 wget 命令,下载所需的插件hadoop-eclipse-plugin-2
将插件hadoop-eclipse-plugin-2
jar,从/data/hadoop3目录下,拷贝到/apps/eclipse/plugins 的插件目录下
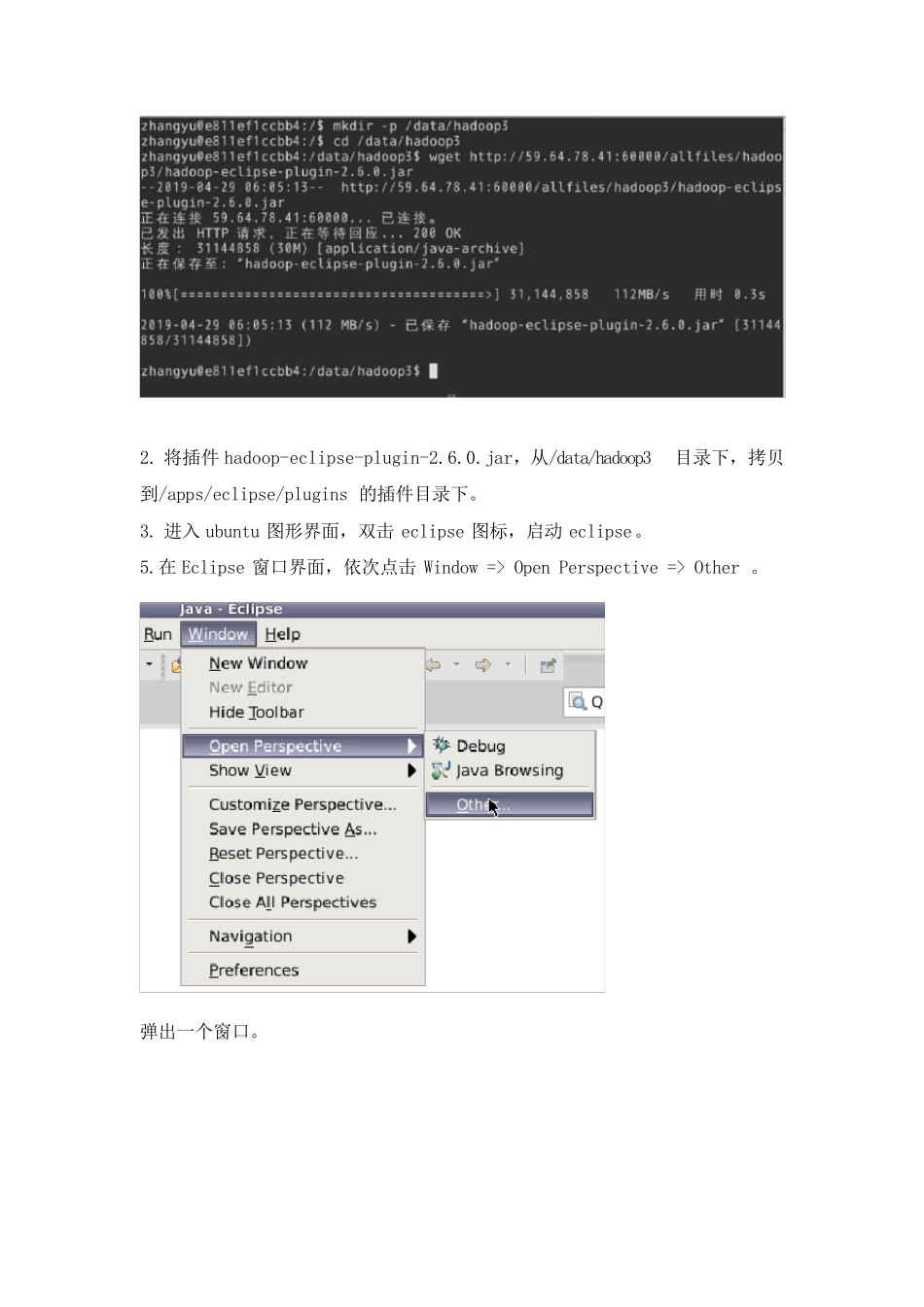
进入 ubuntu 图形界面,双击 eclipse 图标,启动 eclipse
在 Eclipse 窗口界面,依次点击 Window => Open Perspective => Other
弹出一个窗口
选择Map/Reduce,并点击OK,可以看到窗口中,有三个变化
(左侧项目浏览器、右上角操作布局切换、面板窗口) 如果在 win