HADOOP表操作 1、hadoop 简单说明 hadoop 数据库中的数据是以文件方式存存储
一个数据表即是一个数据文件
hadoop 目前仅在 LINUX 的环境下面运行
使用 hadoop 数据库的语法即 hiv e 语法
(可百度 hiv e 语法学习) 通过 s_crt 连接到主机
使用 SCRT 连接到主机,输入 hiv e 命令,进行 hadoop 数据库操作
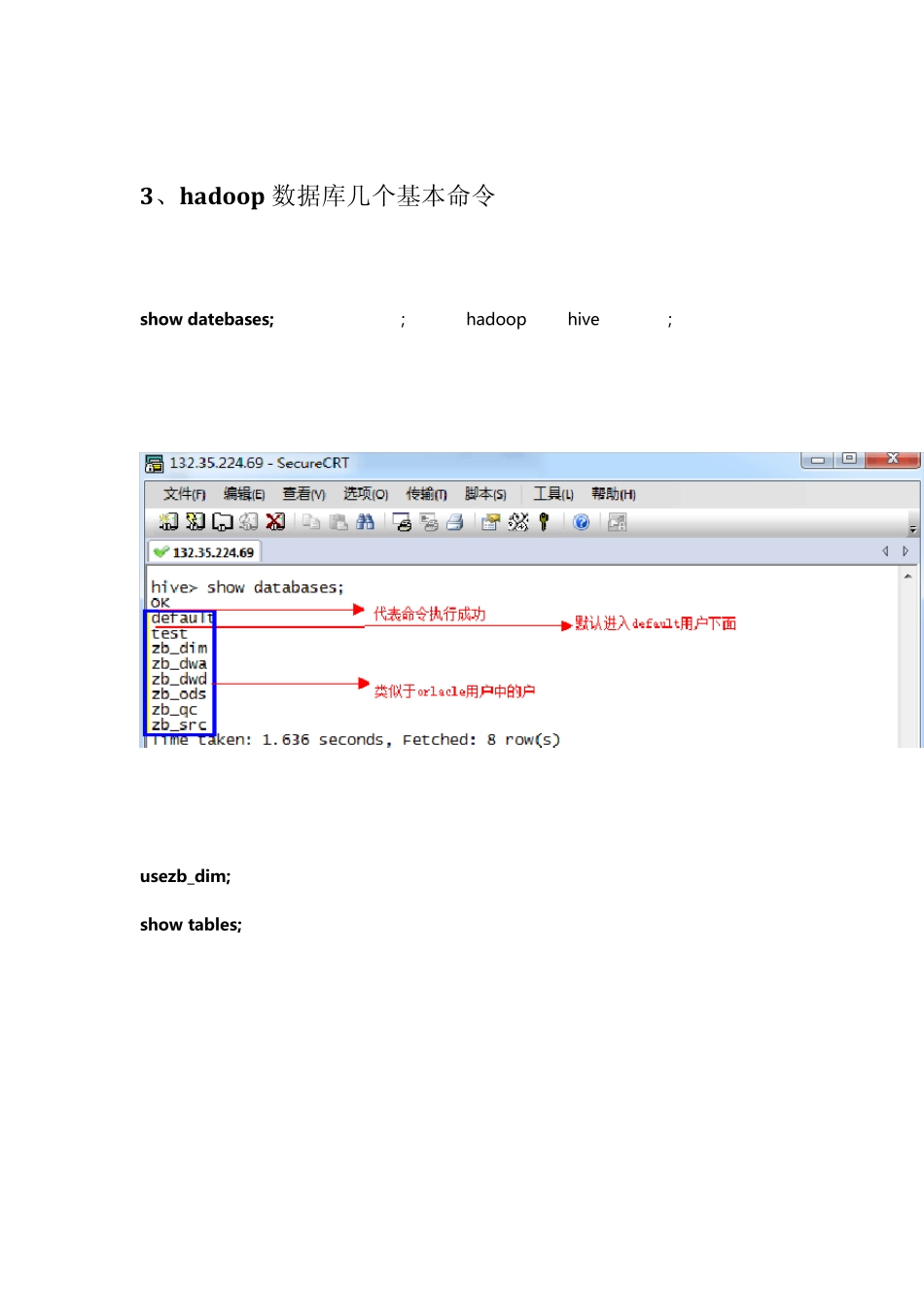
2、使用 hive 进行 HADOOP 数据库操作 3、hadoop 数据库几个基本命令 show datebases; 查看数据库内容; 注意:hadoop 用的 hive 语法用“;”结束,代表一个命令输入完成
usezb_dim; show tables; 4、在 hadoop 数据库上面建表; a1: 了解 hadoop 的数据类型 int 整型; bigint 整型,与 int 的区别是长度在于 int; int,bigint 相当于 oralce 的 number 型,但是不带小数点
doubble 相当于 oracle 的 numbe 型,可带小数点; string 相当于 oralce 的 varchar2(),但是不用带长度; a2: 建表,由于 hadoop 的数据是以文件有形式存放,所以需要指定分隔符
create table zb_dim
dim_bi_test_yu3(id bigint,test1 string,test2 string) row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符 a2
1 查看建表结构: describe A2
2 往表里面插入数据
由于 hadoop 的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用 SFTP