Python实现一个简单的中文分词处理
在Python中,实现一个简单的中文分词处理,我们可以采用基于规则的方法,比如最大匹配法、最小匹配法、双向匹配法等
但更常见且效果更好的是使用现有的分词库,如jieba分词
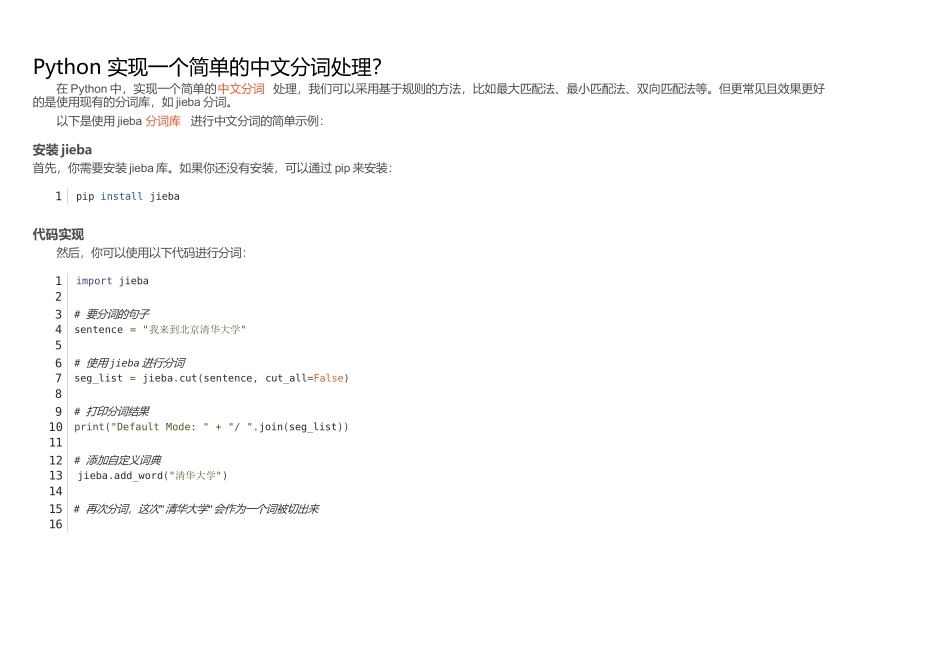
以下是使用jieba分词库进行中文分词的简单示例:安装jieba首先,你需要安装jieba库
如果你还没有安装,可以通过pip来安装:1pipinstalljieba代码实现然后,你可以使用以下代码进行分词:1importjieba23#要分词的句子4sentence="我来到北京清华大学"56#使用jieba进行分词7seg_list=jieba
cut(sentence,cut_all=False)89#打印分词结果10print("DefaultMode:"+"/"
join(seg_list))1112#添加自定义词典13jieba
add_word("清华大学")1415#再次分词,这次"清华大学"会作为一个词被切出来1617seg_list=jieba
cut(sentence,cut_all=False)print("CustomDictionary:"+"/"
join(seg_list))在上面的代码中,我们首先导入了jieba库,然后定义了一个要分词的句子
cut函数用于执行分词,cut_all=False表示采用精确模式进行分词
默认情况下,jieba已经包含了一个较为完善的词典,但对于一些专业术语或新词,可能需要添加自定义词典来提高分词准确性
如果你想要自己实现一个简单的分词器,那么可能需要考虑基于统计的分词方法,这通常涉及到训练语言模型,并利用模型的分词概率来进行分词
然而,这种方法通常比较复杂,需要大量的语料库和计算资源,并且效果也不一定比现成的分词库好
因此,对于大多数应用场景,使用现成的分词库是一个更好的选择