第一章 引言1
1 讨论背景数据发布环境中存在的隐私泄露问题使得数据发布隐私泄露控制技术的讨论成为学术界和工业界关注的一个焦点
数据发布中的原始数据由记录构成,每个记录均与一个个体相对应,数据的属性分为标识符、准标识符、敏感属性三类
数据发布时直接删除标识符以保护个体隐私
但是可能存在攻击者通过准标识符与外部公开的数据源进行链接攻击(Linking Attack) [1],导致个体隐私的泄露
讨论表明,这种链接攻击可以识别大量美国公民的身份[1]
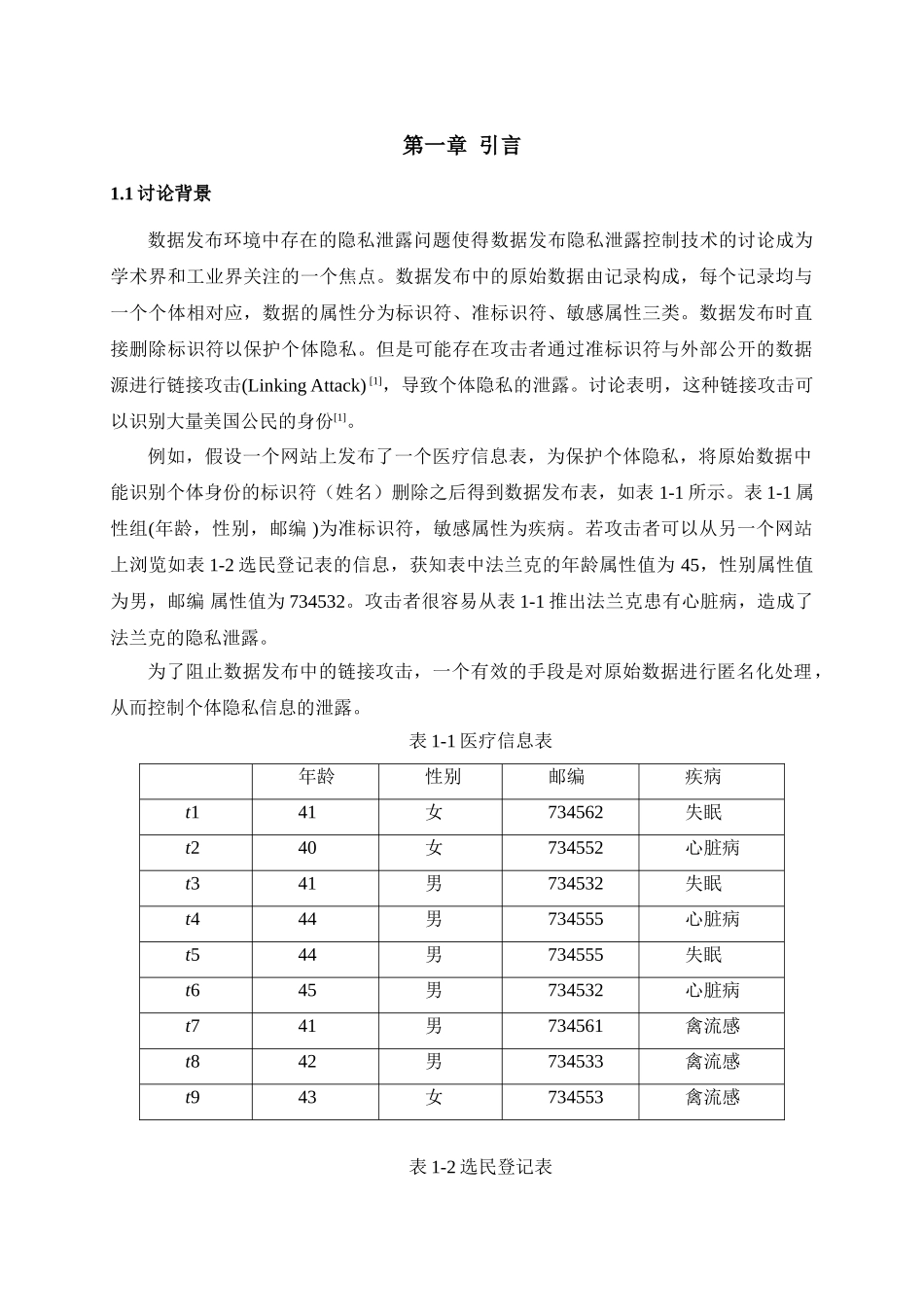
例如,假设一个网站上发布了一个医疗信息表,为保护个体隐私,将原始数据中能识别个体身份的标识符(姓名)删除之后得到数据发布表,如表 1-1 所示
表 1-1 属性组(年龄,性别,邮编 )为准标识符,敏感属性为疾病
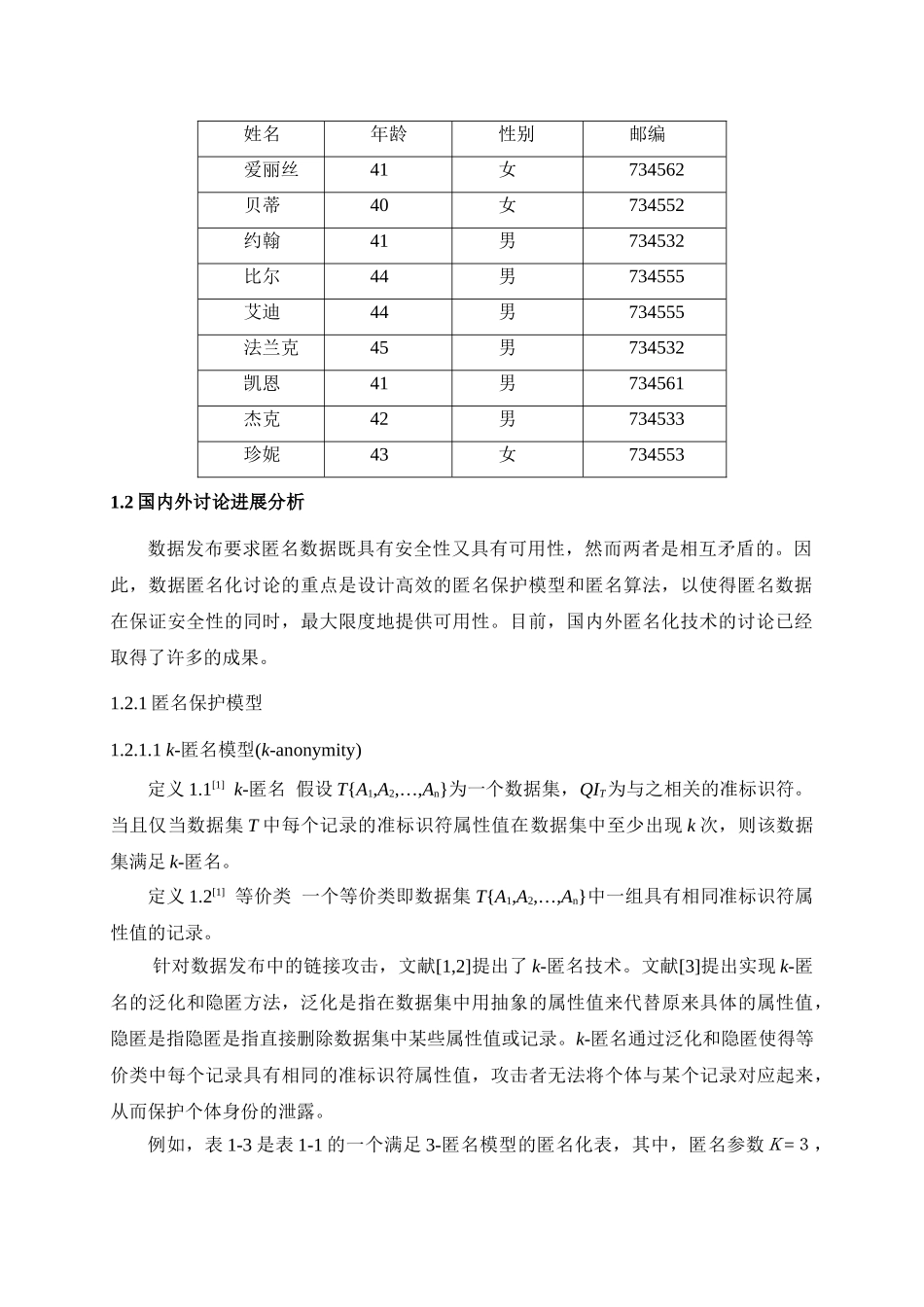
若攻击者可以从另一个网站上浏览如表 1-2 选民登记表的信息,获知表中法兰克的年龄属性值为 45,性别属性值为男,邮编 属性值为 734532
攻击者很容易从表 1-1 推出法兰克患有心脏病,造成了法兰克的隐私泄露
为了阻止数据发布中的链接攻击,一个有效的手段是对原始数据进行匿名化处理,从而控制个体隐私信息的泄露
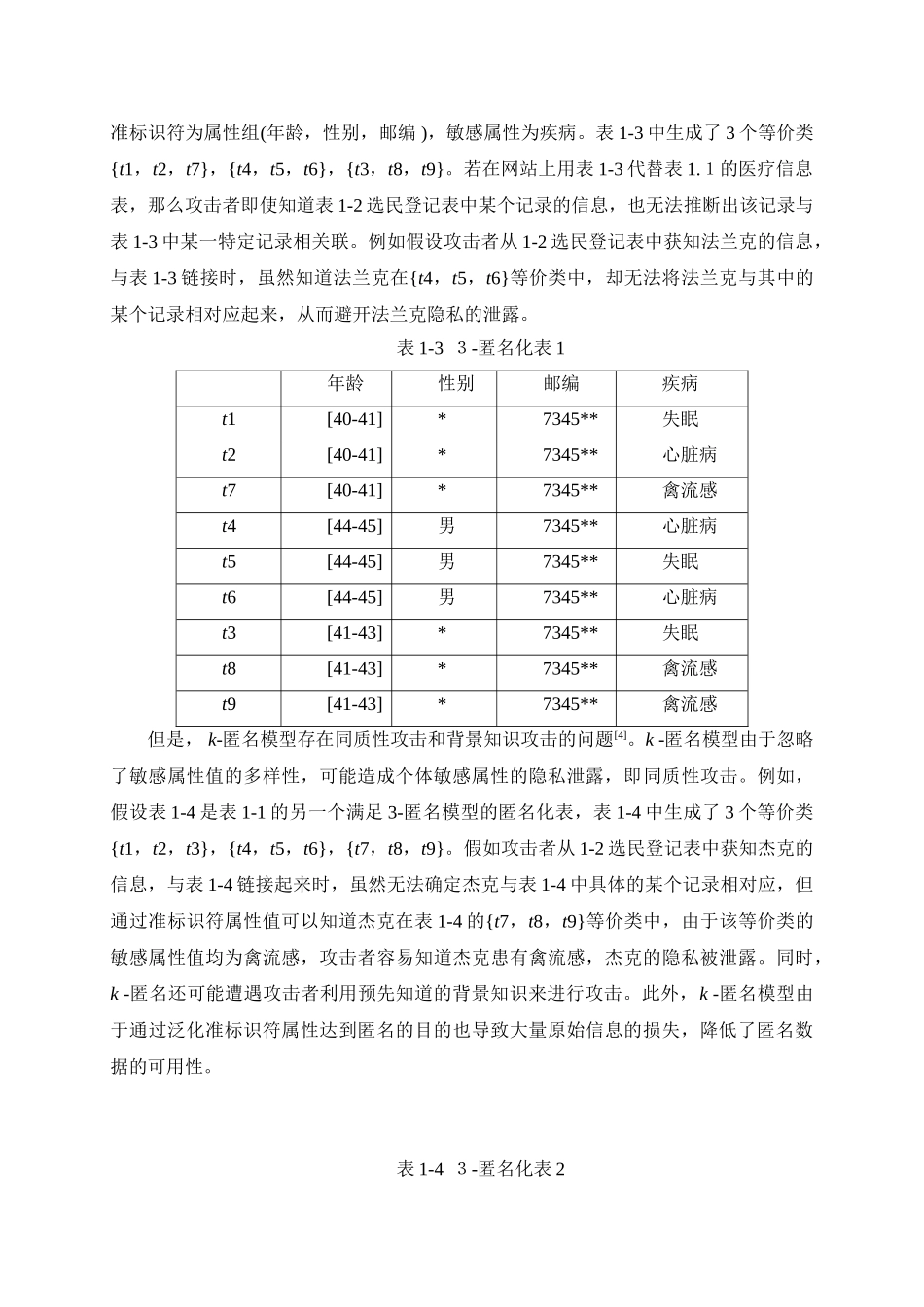
表 1-1 医疗信息表年龄性别邮编疾病t141女734562失眠t240女734552心脏病t341男734532失眠t444男734555心脏病t544男734555失眠t645男734532心脏病t741男734561禽流感t842男734533禽流感t943女734553禽流感表 1-2 选民登记表姓名年龄性别邮编爱丽丝41女734562贝蒂40女734552约翰41男734532比尔44男734555艾迪44男734555法兰克45男734532凯恩41男734561杰克42男734533珍妮43女7345531
2 国内外讨论进展分析数据发布要求匿名数据既具有安全性又具有可用性,然而两者是相互矛盾的