一、数据分析平台层次解析大数据分析处理架构图数据源: 除该种方法之外,还可以分为离线数据、近似实时数据和实时数据
根据图中的分类其实就是说明了数据存储的结构,而特别要说的是流数据,它的核心就是数据的连续性和快速分析性;计算层: 内存计算中的 Spark 是 UC Berkeley 的最新作品,思路是利用集群中的所有内存将要处理的数据加载其中,省掉很多 I/O 开销和硬盘拖累,从而加快计算
而 Impala 思想来源于 Google Dremel,充分利用分布式的集群和高效存储方式来加快大数据集上的查询速度,这也就是我上面说到的近似实时查询;底层的文件系统当然是 HDFS 独大,也就是 Hadoop 的底层存储,现在大数据的技术除了微软系的意外,基本都是 HDFS 作为底层的存储技术
上层的 YARN 就是 MapReduce 的第二版,和在一起就是 Hadoop 最新版本
基于之上的应用有Hive,Pig Latin,这两个是利用了 SQL 的思想来查询 Hadoop 上的数据
关键: 利用大数据做决策支持
R 可以帮你在大数据上做统计分析,利用 R 语言和框架可以实现很专业的统计分析功能,并且能利用图形的方式展现;而Mahout 就是一个集数据挖掘、决策支持等算法于一身的工具,其中包含的都是基于 Hadoop 来实现的经典算法,拿这个作为数据分析的核心算法集来参考还是很好的
如此一个决策支持系统要怎么展现呢
其实这个和数据挖掘过程中的展现一样,无非就是通过表格和图标图形来进行展示,其实一份分类详细、颜色艳丽、数据权威的数据图标报告就是呈现给客户的最好方式
至于用什么工具来实现,有两个是最好的数据展现工具,Tableau 和 Pentaho,利用他们最为数据展现层绝对是最好的选择
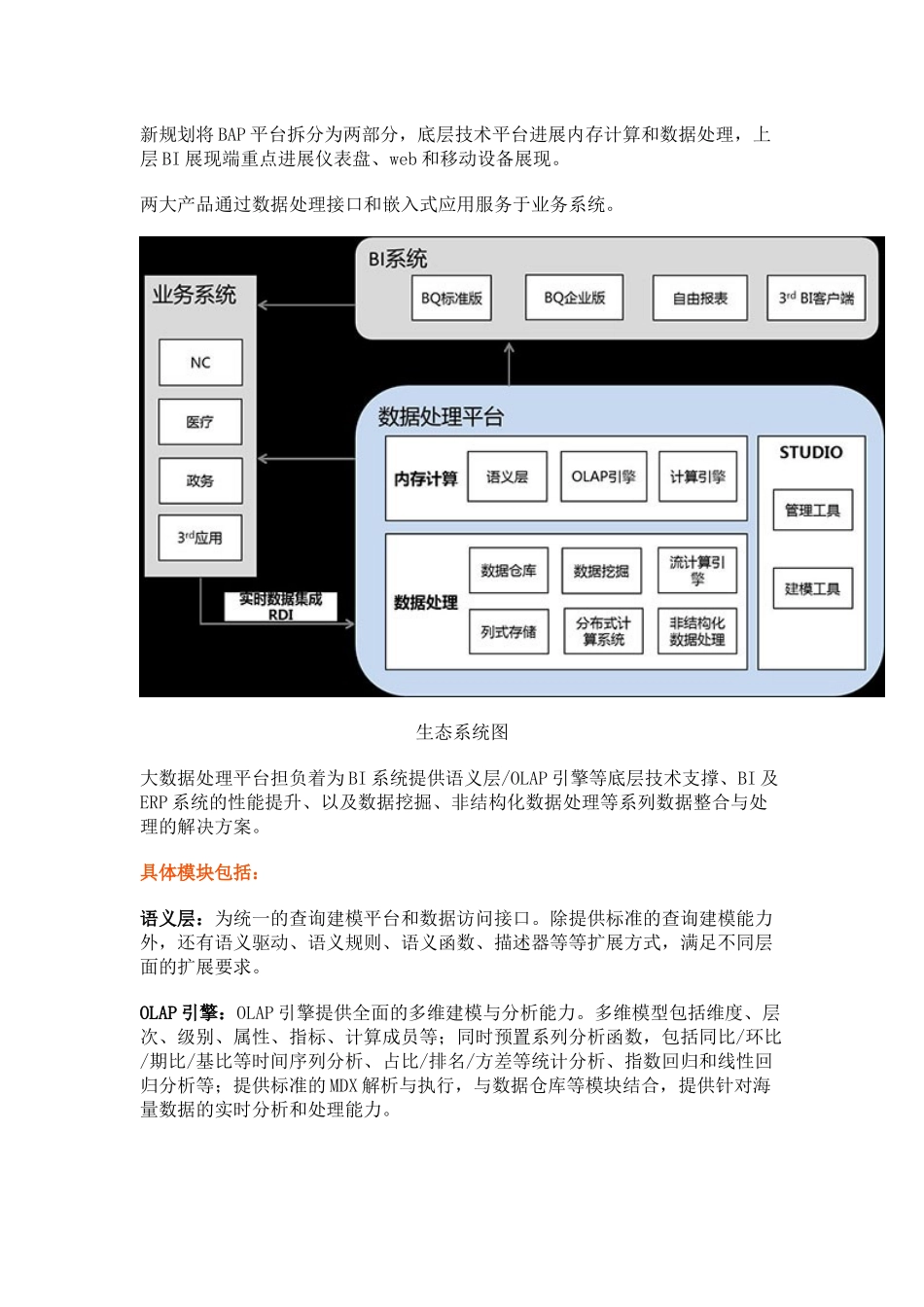
二、规划的数据平台产品 AE(Accelerate Engine)支持下一代企业计算关键技术的