常用SPSS数据处理方法,你都会吗
数据编辑处理是在统计和分析数据时,第一步要做的
尤其是当面对大量数据时,数据处理是一个重要的过程,可以达到提高处理效率及精度的目的
为配合进行更好的分析,研究过程过可能涉及到以下数据处理工作:1、定义变量名2、制定数据标签3、数据编码4、计算变量5、无效样本处理6、特殊值处理等定义变量定义变量,就是给每个指标起名字
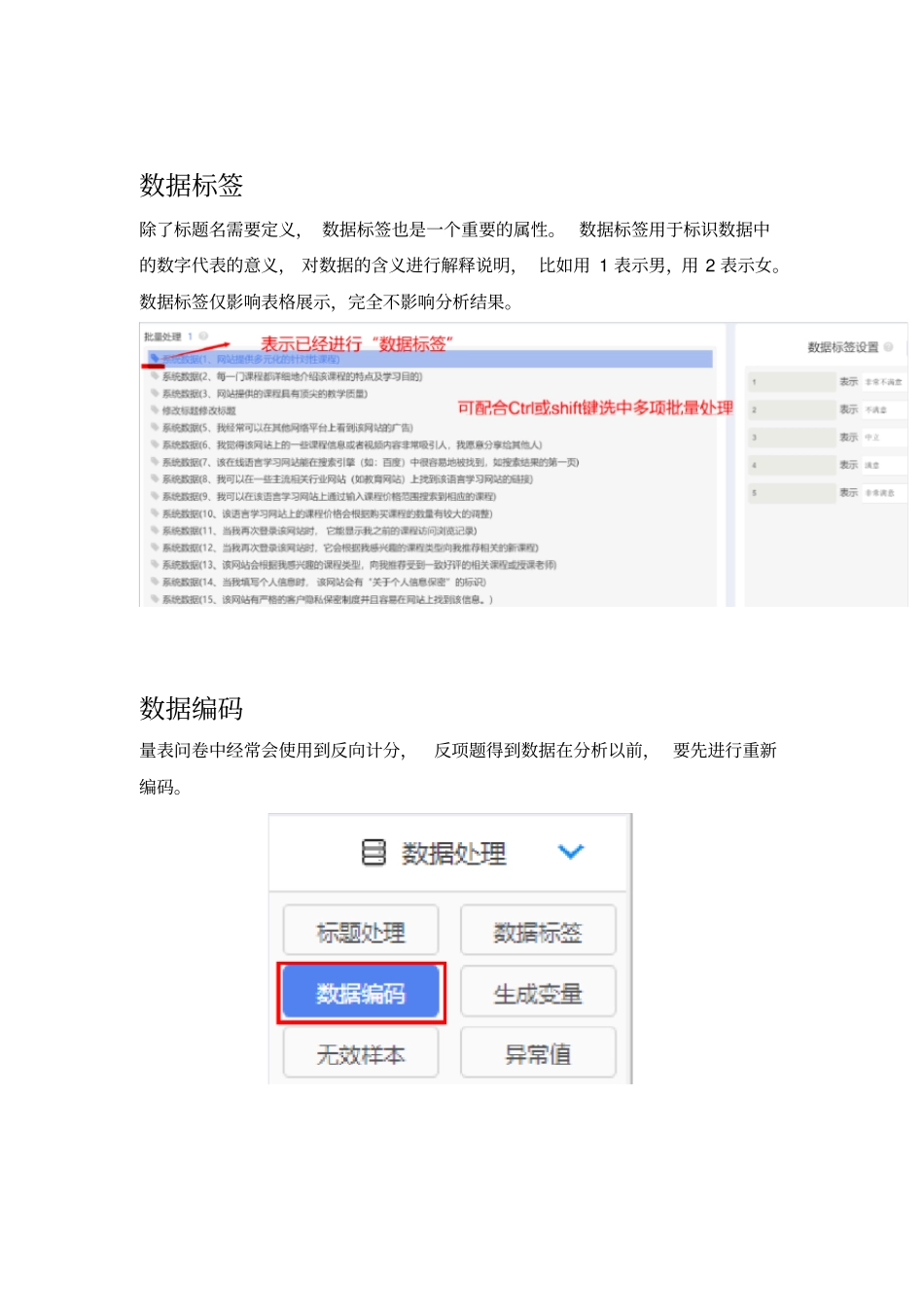
每个变量都需要有对应的变量名,以便得到更规范的表格呈现和操作体验,spssau中通过“标题修改”定义变量名,一般用于以下情况:上传数据后,对不规范标题修改完成数据编码后,进行标题修改完成生成变量后,进行标题修改有多余无意义的标题,进行删除标题(一次只能删除一个标题)数据标签除了标题名需要定义,数据标签也是一个重要的属性
数据标签用于标识数据中的数字代表的意义,对数据的含义进行解释说明,比如用1表示男,用2表示女
数据标签仅影响表格展示,完全不影响分析结果
数据编码量表问卷中经常会使用到反向计分,反项题得到数据在分析以前,要先进行重新编码
数据编码通常除了用于处理反项题,还会用于数据组合
比如1代表高中,2代表大专,3代表本科,4代表硕士,5代表博士
希望组合成三组分别是:本科以下,本科,硕士及以上
则可处理为:1->1,2->1,3->2,4->3,5->3,最终数字1代表本科以下,2代表本科,3代表硕士及以上无效样本在数据分析之前,首先需要进行数据查看,包括数据中是否有异常值,无效样本等
如果有无效样本则需要进行处理,然后再进行分析
另外如果数据中有异常值也需要进行处理后再进行分析
无效样本会干扰分析研究,扭曲数据结论等,因而在分析前先对无效样本进行标识显示尤其必要
如果数据来源为问卷,则很可能出现无效样本,因为填写问卷的样本是否真实填写无从判定;如果数据库下载或者使用二手数据等,也可能出现大量缺失数据等无效样本