(1)t分布:设x1,x2,…,xn是来自正态总体N(μ,σ2)的一个样本,则有:¯x~N(μ,),对样本均值¯x施行标准化变换,则有:u=¯x−μσ/√n=√n(¯x−μ)σ~N(0,1),当用样本标准s代替上式中的总体标准差σ,则上式u变量改为t变量,标准正态分布N(0,1)也随之改为“自由度为n-1的t分布”,记为t(n-1),即:t=√n(¯x−μ)s=√n(¯x−μ)√1n−1∑i=1n(xi−¯x)2~t(n-1)
(2)χ2分布:自由度为n-1的χ2分布的概率密度函数在正半轴上呈偏态分布
(3)F分布:设有两个独立的正态总体N(μ1,σ2)和N(μ2,σ2),它们的方差相等
又设x1,x2,…,xn是来自N(μ1,σ2)的一个样本;y1,y2,…,ym是来自N(μ2,σ2)的一个样本,两个样本相互独立
它们的样本方差比的分布是自由度为n-1和m-1的F分布,其中n-1称为分子自由度或第1自由度;m-1称为分母自由度或第2自由度
F分布的概率密度函数在正半轴上呈偏态分布
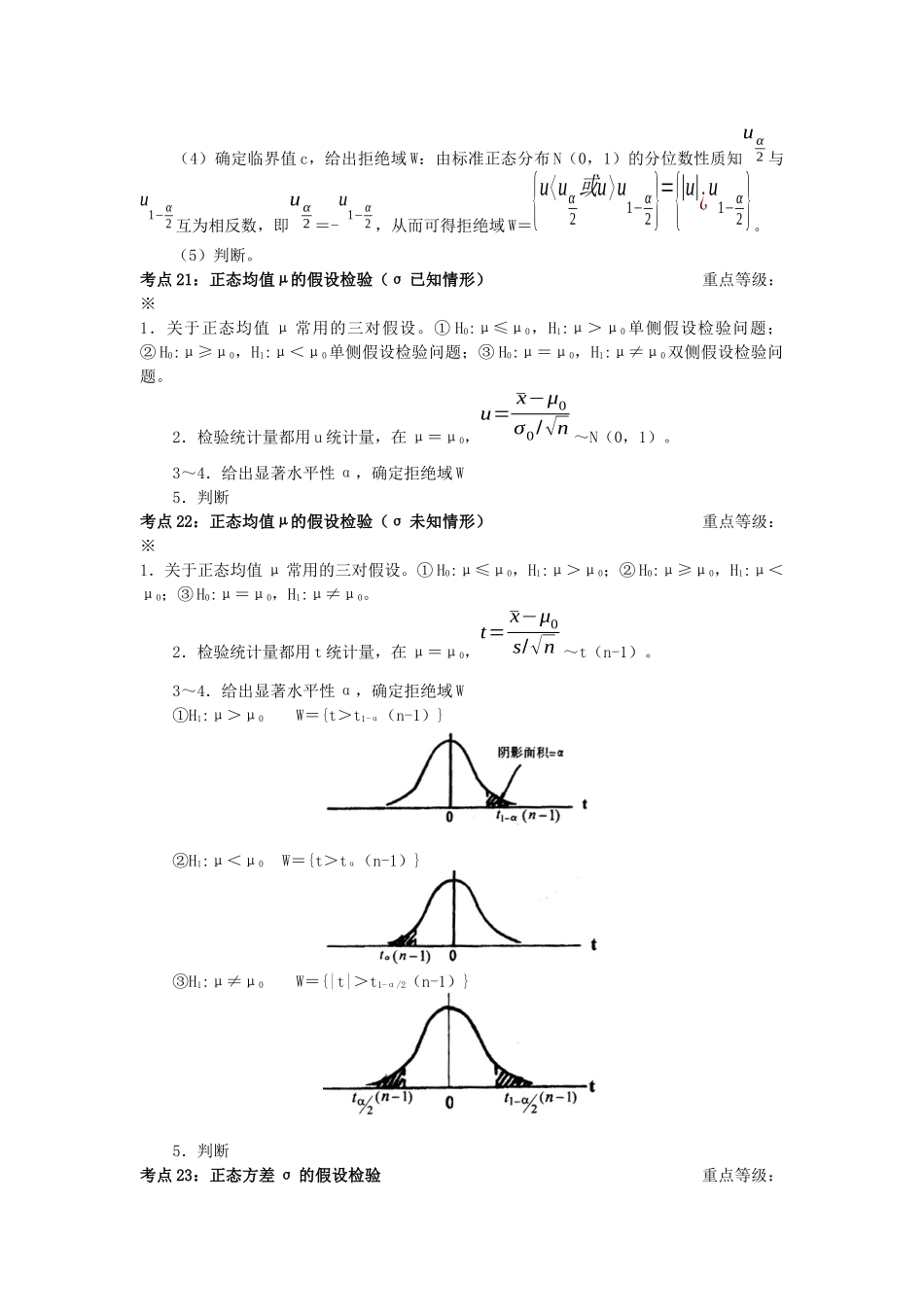
考点17:参数估计重点等级:※参数主要是指:①分布中的未知参数,如二项分布b(1,p)中的p,正态分布N(μ,σ2)中的μ,σ2或σ;②分布的均值E(X)、方差Var(X)等未知特征数;③其他未知参数,如某事件的概率P(A)等
上述未知参数都需要根据样本和参数的统计含义选择适宜的统计量并作出估计
参数估计有两种基本形式:点估计与区间估计
考点18:点估计重点等级:※※※※1.点估计优良性标准无偏性是表示估计量优良性的一个重要标准,只要有可能,应该尽可能选用无偏估计量,或近似无偏估计量
有效性是判定估计量优良性的另一个标准
2.求点估计的方法--矩法估计由于均值与方差在统计学中统称为矩,总体均值与总体方差属于总体矩,样本均值与样本方差属于样本矩
获得未知参数的点估计的方法称为矩法估计
矩法估计简单