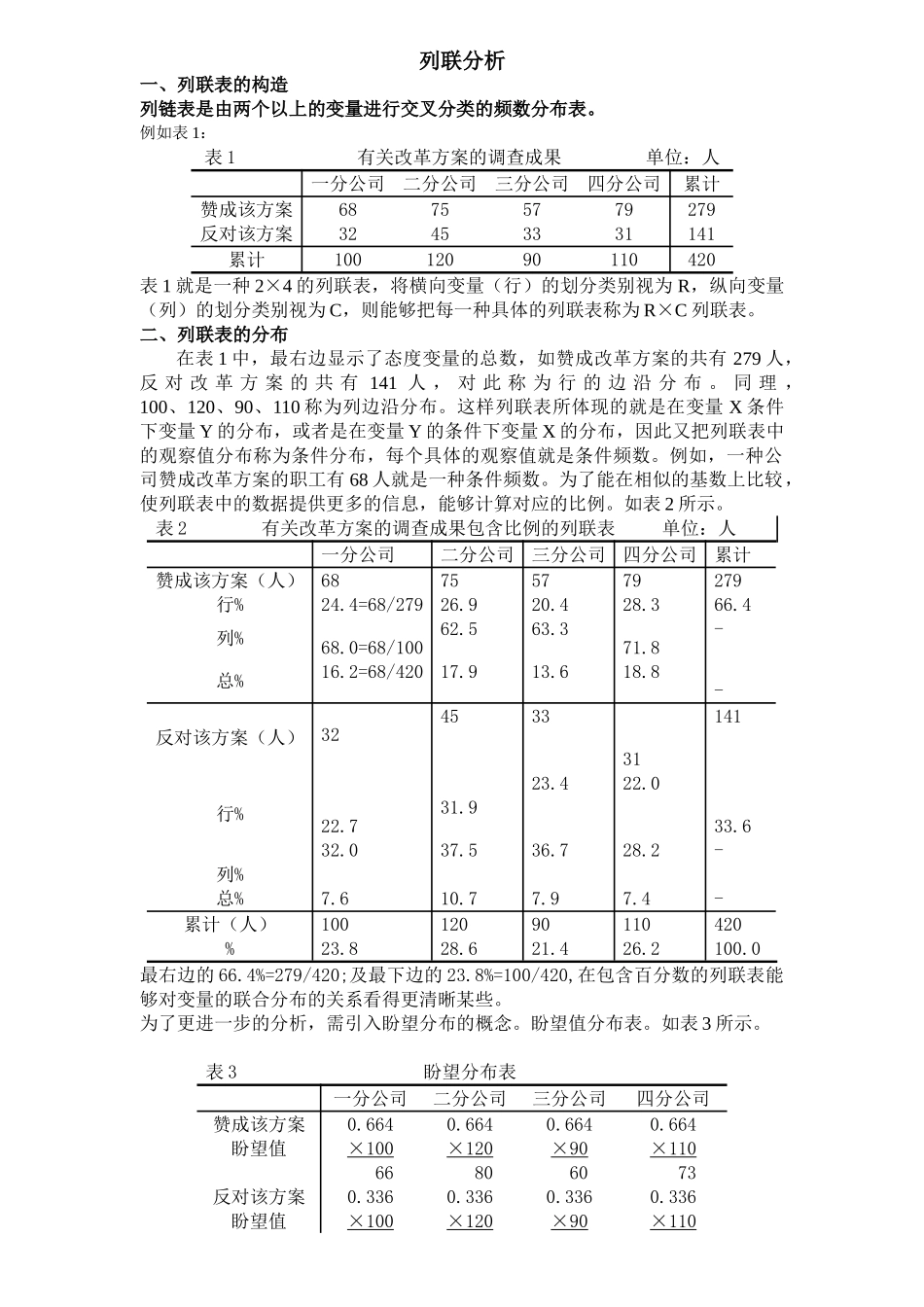
列联分析一、列联表的构造列链表是由两个以上的变量进行交叉分类的频数分布表
例如表1:表1有关改革方案的调查成果单位:人一分公司二分公司三分公司四分公司累计赞成该方案68755779279反对该方案32453331141累计10012090110420表1就是一种2×4的列联表,将横向变量(行)的划分类别视为R,纵向变量(列)的划分类别视为C,则能够把每一种具体的列联表称为R×C列联表
二、列联表的分布在表1中,最右边显示了态度变量的总数,如赞成改革方案的共有279人,反对改革方案的共有141人,对此称为行的边沿分布
同理,100、120、90、110称为列边沿分布
这样列联表所体现的就是在变量X条件下变量Y的分布,或者是在变量Y的条件下变量X的分布,因此又把列联表中的观察值分布称为条件分布,每个具体的观察值就是条件频数
例如,一种公司赞成改革方案的职工有68人就是一种条件频数
为了能在相似的基数上比较,使列联表中的数据提供更多的信息,能够计算对应的比例
表2有关改革方案的调查成果包含比例的列联表单位:人一分公司二分公司三分公司四分公司累计赞成该方案(人)68755779279行%24
4=68/27926
0=68/10062
8-总%16
2=68/42017
8-反对该方案(人)32453331141行%22
4-累计(人)10012090110420%23
0最右边的66
4%=279/420;及最下边的23
8%=100/420,在包含百分数的列联表能够对变量的联合分布的关系看得更清晰某些
为了更进一步的分析,需引入盼望分布的概念
盼望值分布表