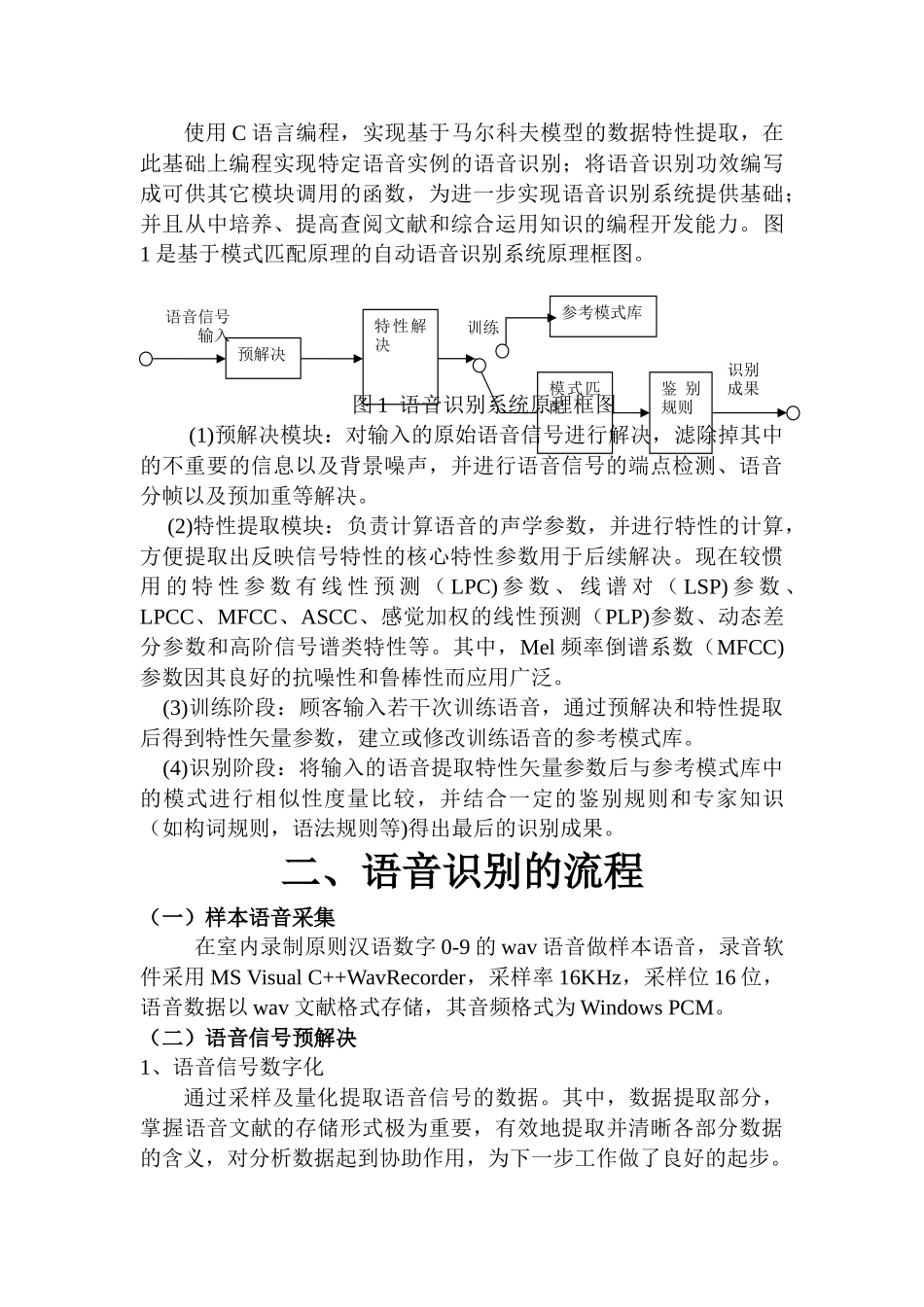
语音识别流程分析摘要:语言识别是将人类自然语言的声音信号,通过计算机自动转换为与之相对应的文字符号的一门新兴技术,属于模式识别的一种分支
语音识别的成果能够通过屏幕显示出文字符号,也能够存储在文本文献中
语音识别技术能够把语音信息直接转换成文字信息,对于中文信息解决来说,无疑是一种最抱负、最自然的中文输入方式
本文首先分析了语音识别的原理,在此基础上进行语音识别的流程分析,重要内容有:提取语音、端点检测、特性值提取、训练数据、语音识别
选用HMM隐马尔科夫模型,基于VC编译环境下的的多线程编程,实现算法的并行运算,提高了语音识别的效率
实验成果表明:所设计的程序满足语音识别系统的基本规定
核心词:语音识别预解决Mel倒谱系数HMM隐马尔科夫模式OpenMP编程前言语音识别是解决机器“听懂”人类语言的一项技术
作为智能计算机研究的主导方向和人机语音通信的核心技术,语音识别技术始终受到各国科学界的广泛关注
如今,随着语音识别技术研究的突破,其对计算机发展和社会生活的重要性日益凸现出来
以语音识别技术开发出的产品应用领域非常广泛,如声控电话交换、信息网络查询、家庭服务、宾馆服务、医疗服务、银行服务、工业控制、语音通信系统等,几乎进一步到社会的每个行业和每个方面
广泛意义上的语音识别按照任务的不同能够分为4个方向:说话人识别、核心词检出、语言辨识和语音识别
说话人识别技术是以话音对说话人进行区别,从而进行身份鉴别和认证的技术
核心词检出技术应用于某些含有特定规定的场合,只关注那些包含特定词的句子
语言辨识技术是通过分析解决一种语音片断以鉴别其所属语言种类的技术,本质上也是语音识别技术的一种方面
语音识别就是普通人们所说的以说话的内容作为识别对象的技术,它是4个方面中最重要和研究最广泛的一种方向,也是本文讨论的重要内容
语音识别技术,也被称为自动语音AutomaticSpeechRe