AI 图像视觉处理技术简介计算机视觉是一门研究如何使机器”看“的科学,作为一个学科,它试图建立能够从图像或多维数据中获取”信息“的人工智能系统
一、检测跟踪1
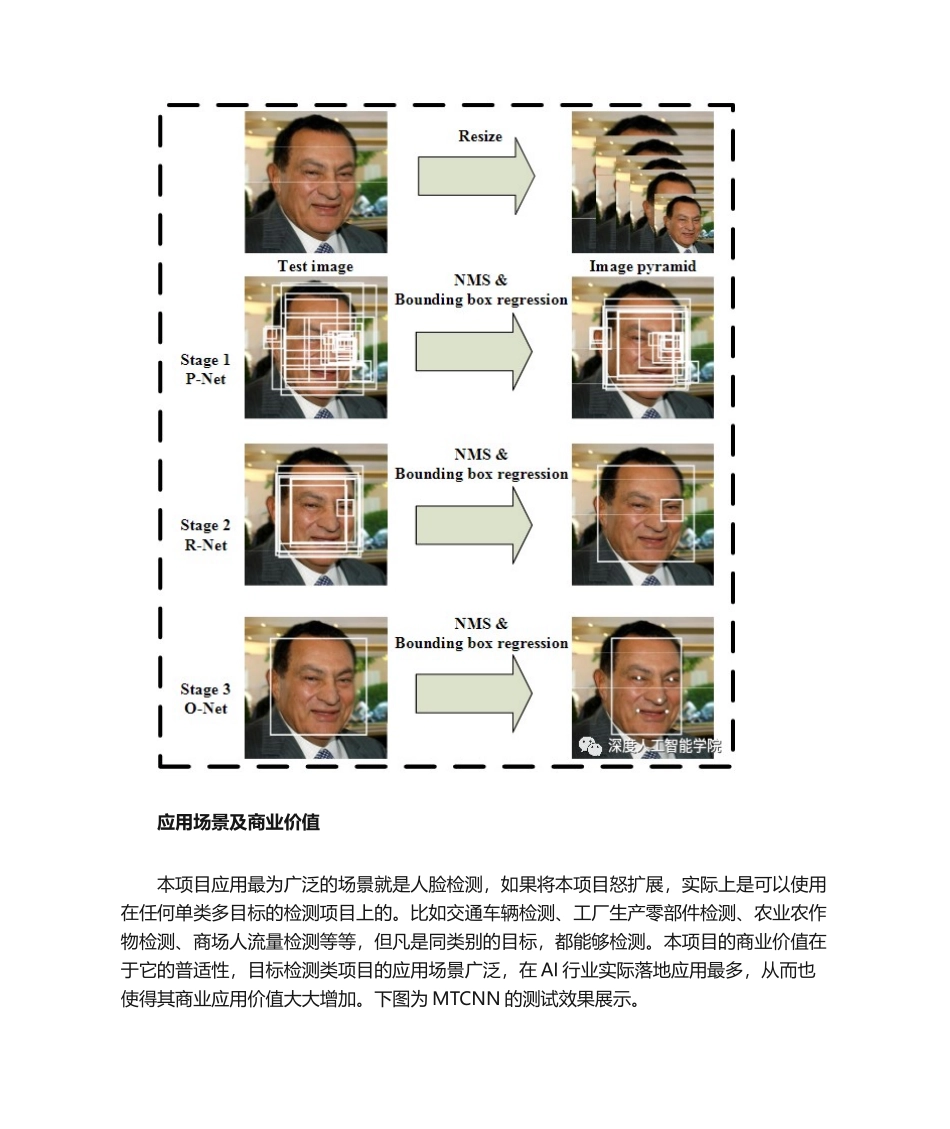
MTCNNMTCNN 是比较经典快速的人脸检测技术,它可实现两个任务:人脸检测与人脸关键点检测
这个过程由三个级联的轻量级 CNN 完成:PNet,RNet 和 Onet;图像数据先后经过这三个网络的处理,最终输出人脸检测和关键点检测结果
技术思想及原理分析本项目的一大技术亮点就是使用了级联卷积的思想,将复杂问题简单化,化整为零,逐一攻破,既减小了问题的难度、提高了模型训练效率,还为以后解决这一类问题提供了可参考的方法
项目中的级联思想、图像金字塔、IOU、NMS、图像坐标缩放及坐标反算等技术在后续的目标检测中仍然能够看到它们的身影
应用场景及商业价值本项目应用最为广泛的场景就是人脸检测,如果将本项目怒扩展,实际上是可以使用在任何单类多目标的检测项目上的
比如交通车辆检测、工厂生产零部件检测、农业农作物检测、商场人流量检测等等,但凡是同类别的目标,都能够检测
本项目的商业价值在于它的普适性,目标检测类项目的应用场景广泛,在 AI 行业实际落地应用最多,从而也使得其商业应用价值大大增加
下图为 MTCNN 的测试效果展示
YOLO 系列You Only Look Once”或“YOLO”是一个对象检测算法的名字,这是 Redmon 等人在 2016 年的一篇研究论文中命名的
YOLO 实现了自动驾驶汽车等前沿技术中使用的实时对象检测
技术思想及原理分析YOLO 的渊源应该从 RCNN 系列说起,比较早的多类别检测识别模型是 RCNN 系列,包含了 RCNN、fast-RCNN 以及 faster-RCNN,但是 RCNN 系列都是两阶段的,就是先检测、再分类,这样虽然说提高了检测分类精度,但是却降低了速度,所以才有