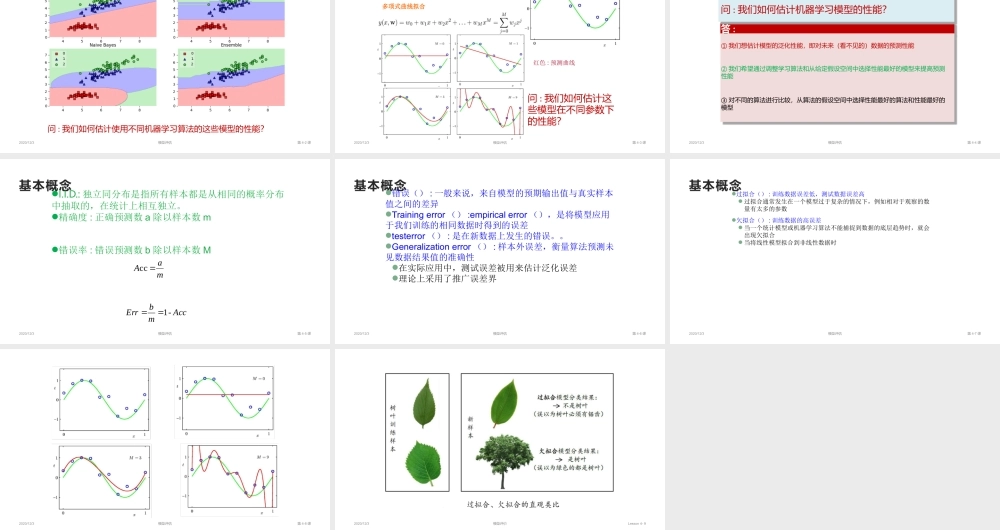
机器学习模型评估的基础2020/12/3模型评估第 4-1 课2020/12/3模型评估第 4-2 课问 : 我们如何估计使用不同机器学习算法的这些模型的性能
2020/12/3模型评估第 4-3 课问 : 我们如何估计这些模型在不同参数下的性能
蓝色 : 观测数据绿色 : 真正的分配多项式曲线拟合红色 : 预测曲线2020/12/3模型评估第 4-4 课问 : 我们如何估计机器学习模型的性能
答 :① 我们想估计模型的泛化性能,即对未来(看不见的)数据的预测性能② 我们希望通过调整学习算法和从给定假设空间中选择性能最好的模型来提高预测性能③ 对不同的算法进行比较,从算法的假设空间中选择性能最好的算法和性能最好的模型基本概念2020/12/3模型评估第 4-5 课I
: 独立同分布是指所有样本都是从相同的概率分布中抽取的,在统计上相互独立
精确度 : 正确预测数 a 除以样本数 m错误率 : 错误预测数 b 除以样本数 MmaAccAccmbErr-1基本概念2020/12/3模型评估第 4-6 课错误() : 一般来说,来自模型的预期输出值与真实样本值之间的差异Training error () :empirical error (),是将模型应用于我们训练的相同数据时得到的误差testerror () : 是在新数据上发生的错误
Generalization error () : 样本外误差,衡量算法预测未见数据结果值的准确性在实际应用中,测试误差被用来估计泛化误差理论上采用了推广误差界基本概念2020/12/3模型评估第 4-7 课过拟合() : 训练数据误差低,测试数据误差高 过拟合通常发生在一个模型过于复杂的情况下,例如相对于观察的数量有太多的参数欠拟合() : 训练数据的高误差 当一个统计模型或机器学习算法不能捕捉到数据