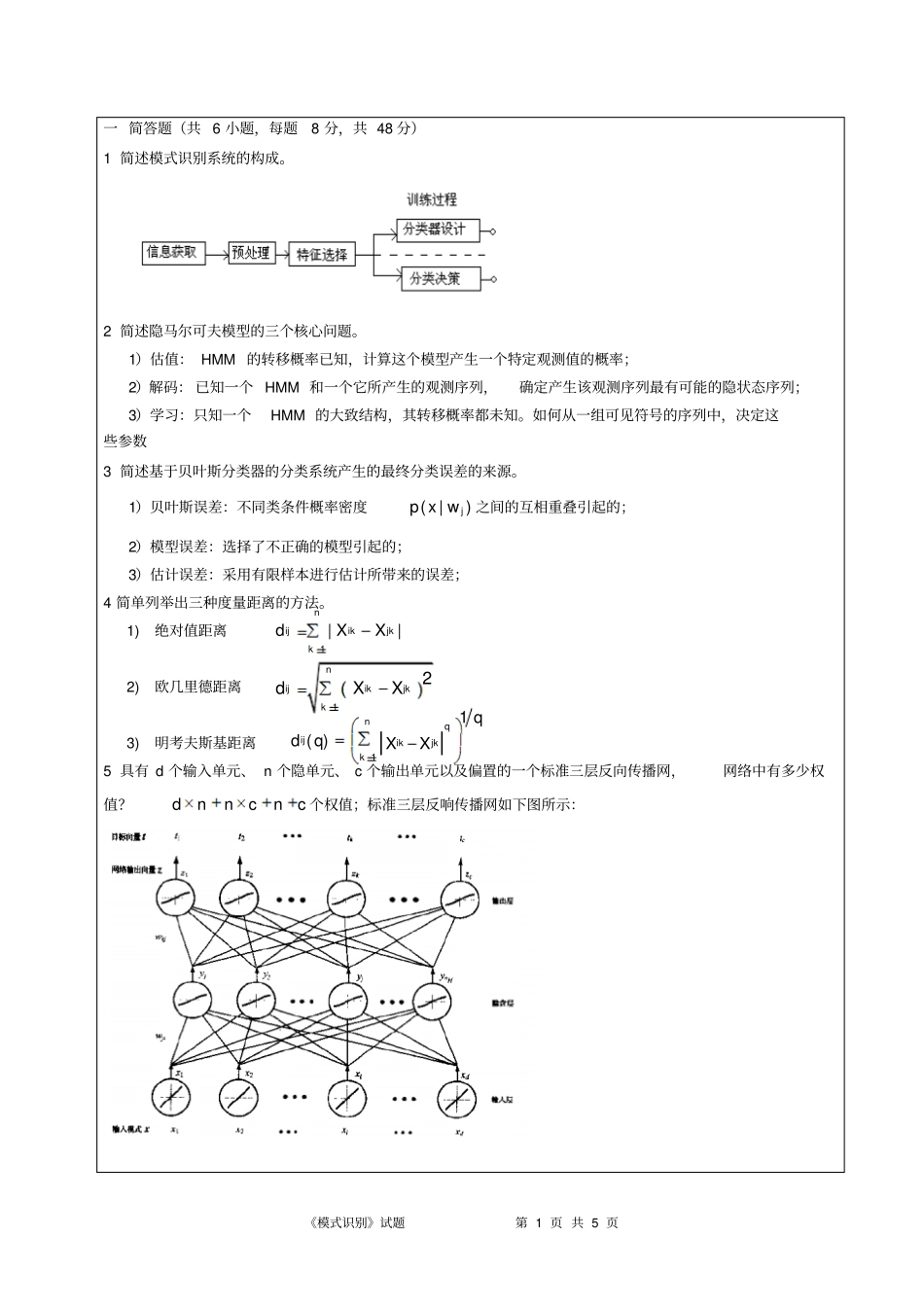
《模式识别》试题第 1 页 共 5 页一 简答题(共 6 小题,每题8 分,共 48 分)1 简述模式识别系统的构成
2 简述隐马尔可夫模型的三个核心问题
1)估值: HMM 的转移概率已知,计算这个模型产生一个特定观测值的概率;2)解码: 已知一个 HMM 和一个它所产生的观测序列,确定产生该观测序列最有可能的隐状态序列;3)学习:只知一个HMM 的大致结构,其转移概率都未知
如何从一组可见符号的序列中,决定这些参数3 简述基于贝叶斯分类器的分类系统产生的最终分类误差的来源
1)贝叶斯误差:不同类条件概率密度( |)jp x w之间的互相重叠引起的;2)模型误差:选择了不正确的模型引起的;3)估计误差:采用有限样本进行估计所带来的误差;4 简单列举出三种度量距离的方法
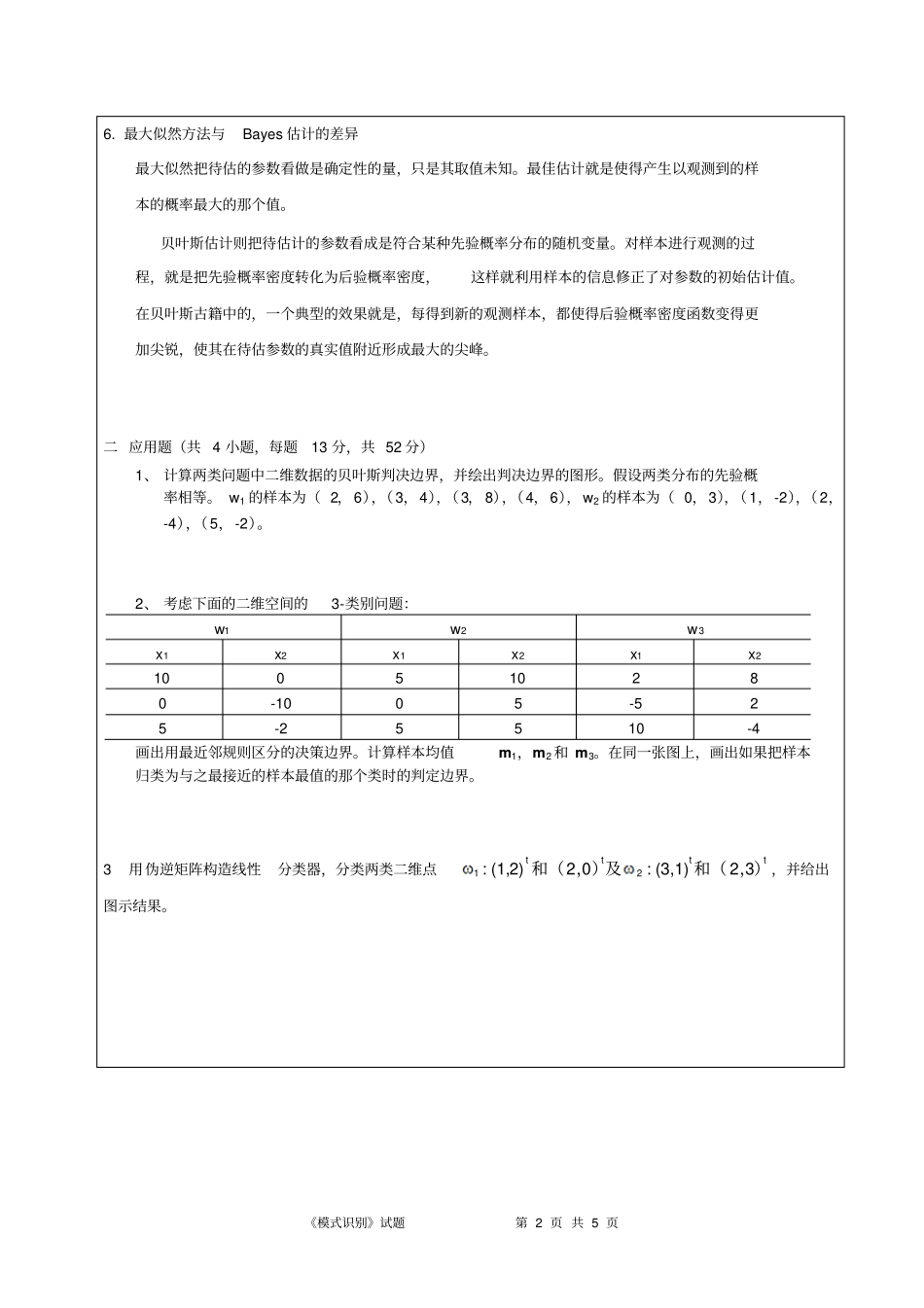
1)绝对值距离2)欧几里德距离3)明考夫斯基距离5 具有 d 个输入单元、 n 个隐单元、 c 个输出单元以及偏置的一个标准三层反向传播网,网络中有多少权值
dnncnc 个权值;标准三层反响传播网如下图所示:1||nijikjkkdXX12nijikjkkdXX11( )||nqijikjkkqdqXX《模式识别》试题第 2 页 共 5 页6
最大似然方法与Bayes 估计的差异最大似然把待估的参数看做是确定性的量,只是其取值未知
最佳估计就是使得产生以观测到的样本的概率最大的那个值
贝叶斯估计则把待估计的参数看成是符合某种先验概率分布的随机变量
对样本进行观测的过程,就是把先验概率密度转化为后验概率密度,这样就利用样本的信息修正了对参数的初始估计值
在贝叶斯古籍中的,一个典型的效果就是,每得到新的观测样本,都使得后验概率密度函数变得更加尖锐,使其在待估参数的真实值附近形成最大的尖峰
二 应用题(共 4 小题,每题13 分,共 52 分)1、 计算两类问题中二维数据的贝叶斯判决边界,并绘出判决边界的图形