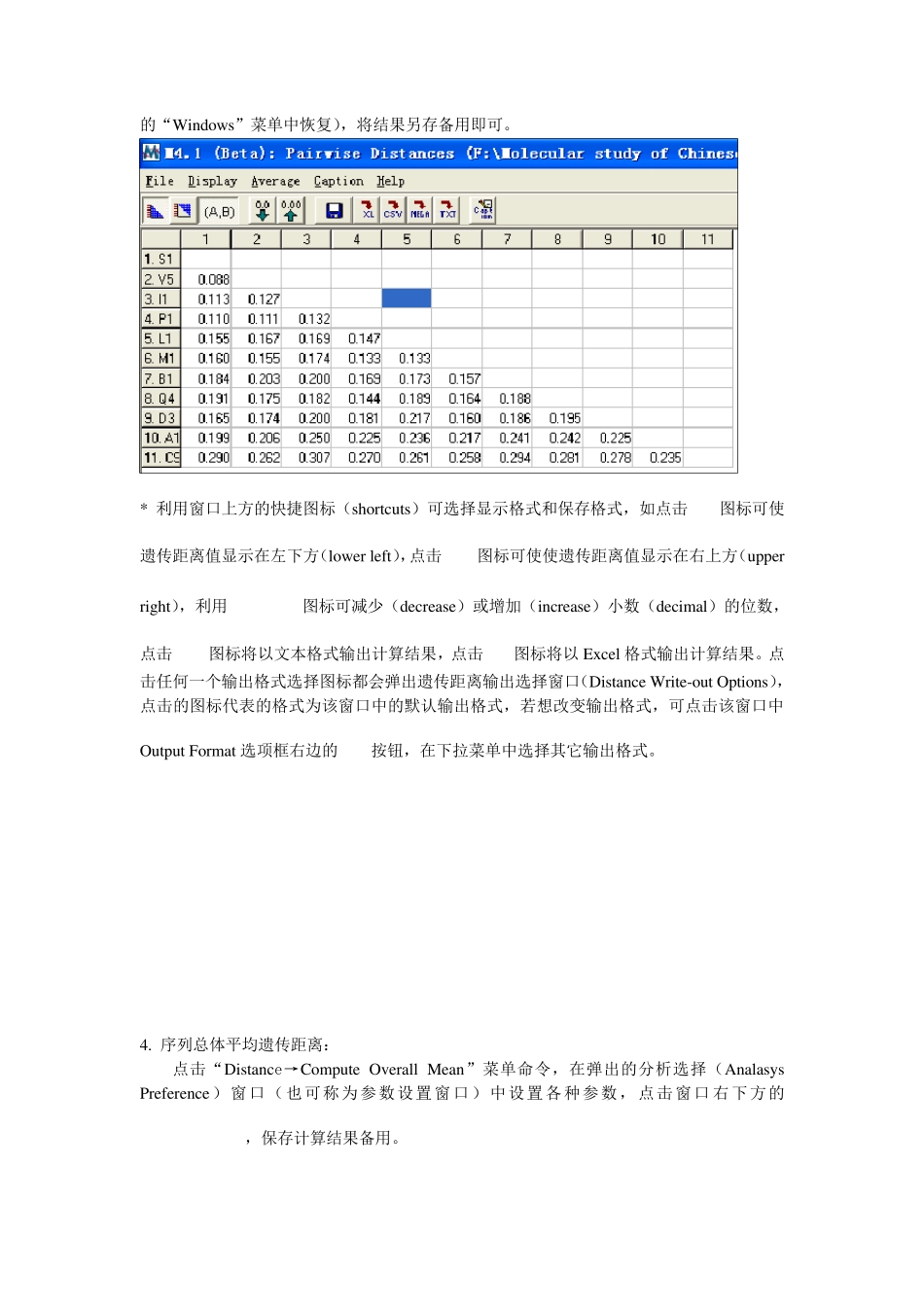
序列间遗传距离的计算 1
导入比对好的“*
meg”格式数据
数据划分 (1)序列数据的基因和域(genes & domains)的指定和选择 在 MEGA 中可对指定范围的序列位点进行分析
虽然经过比对和剪切后的序列通常都可全长用于分析,但对于蛋白质编码基因序列来说,序列的第一位并非总是密码子的第一位,此时要通过该设置指定密码子是从序列的第几位开始(要先通过 Spin 翻译确定),否则软件会将序列的第一位默认为密码子的第一位
具体的操作是:点击“Data→Setup/Select Genes & Domains”(在主窗口和数据管理窗口均可进行此设置),在弹出的“Genes/Domain Organiz ation”小窗口中进行设置;“From”选项用于设置分析的起始位点,“To”用于设置分析的终止位点(设置完成后会在#Site 项显示出选定范围内的位点总数),“Codon Start”用于设置密码子(开放阅读框)从序列的第几位碱基开始读起(如密码子从序列的第一位碱基开始读则设置为“1st site”,依此类推),“Codi…”用于选择是否启动蛋白质翻译功能,该项未选时(如右图)MEGA 将无法将蛋白质编码基因序列翻译成蛋白质序列,数据管理窗口中的按钮将呈灰色显示而失去功能
(2)分类单元的分组及选择 MEGA 可对数据集中指定的分类单元进行分析
为了使选择更加方便 ,通常可对数据 的分类单元进行分组(groups),分组的具体操作是:点击“Data→Setup/Select Taxa & Groups”(在主窗口和数据管理窗口均可进行此设置),在弹出来的“Setup/Select Taxa & Groups”小窗口中根据分析需要对分类单元进行分组,选择需要分析的数据组,点击右下角的“Close”按钮关闭小窗口,即可对选定的组进行相关分析
(3)已分组数据的