一致性哈希算法及jav a 实现 应用场景 在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin)、哈希算法(HASH)、最少连接算法(Least Connection)、响应速度算法(Response Time)、加权法(Weighted )等
其中哈希算法是最为常用的算法
典型的应用场景是: 有N 台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均分发到每台服务器上,每台机器负责 1/N 的服务
常用的算法是对 hash 结果取余数 (hash() mod N):对机器编号从 0 到 N-1,按照自定义的hash()算法,对每个请求的hash()值按 N 取模,得到余数 i,然后将请求分发到编号为 i的机器
但这 样的算法方法存在致命问题,如果某一台机器宕机,那么应该落在该机器的请求就无法得到正确的处理,这时需要将当掉的服务器从算法从去除,此时候会有(N- 1)/N的服务器的缓存数据需要重新进行计算;如果新增一台机器,会有N /(N+1)的服务器的缓存数据需要进行重新计算
对于系统而言,这通常是不可接受的颠簸(因为这意味着大量缓存的失效或者数据需要转移)
那么,如何设 计一个负载均衡策略,使得受到影响的请求尽可能的少呢
在Memcached、Key-Value Store、Bittorrent DHT、LVS 中都采用了 Consistent Hashing 算法,可以说 Consistent Hashing 是分布式系统负载均衡的首选算法
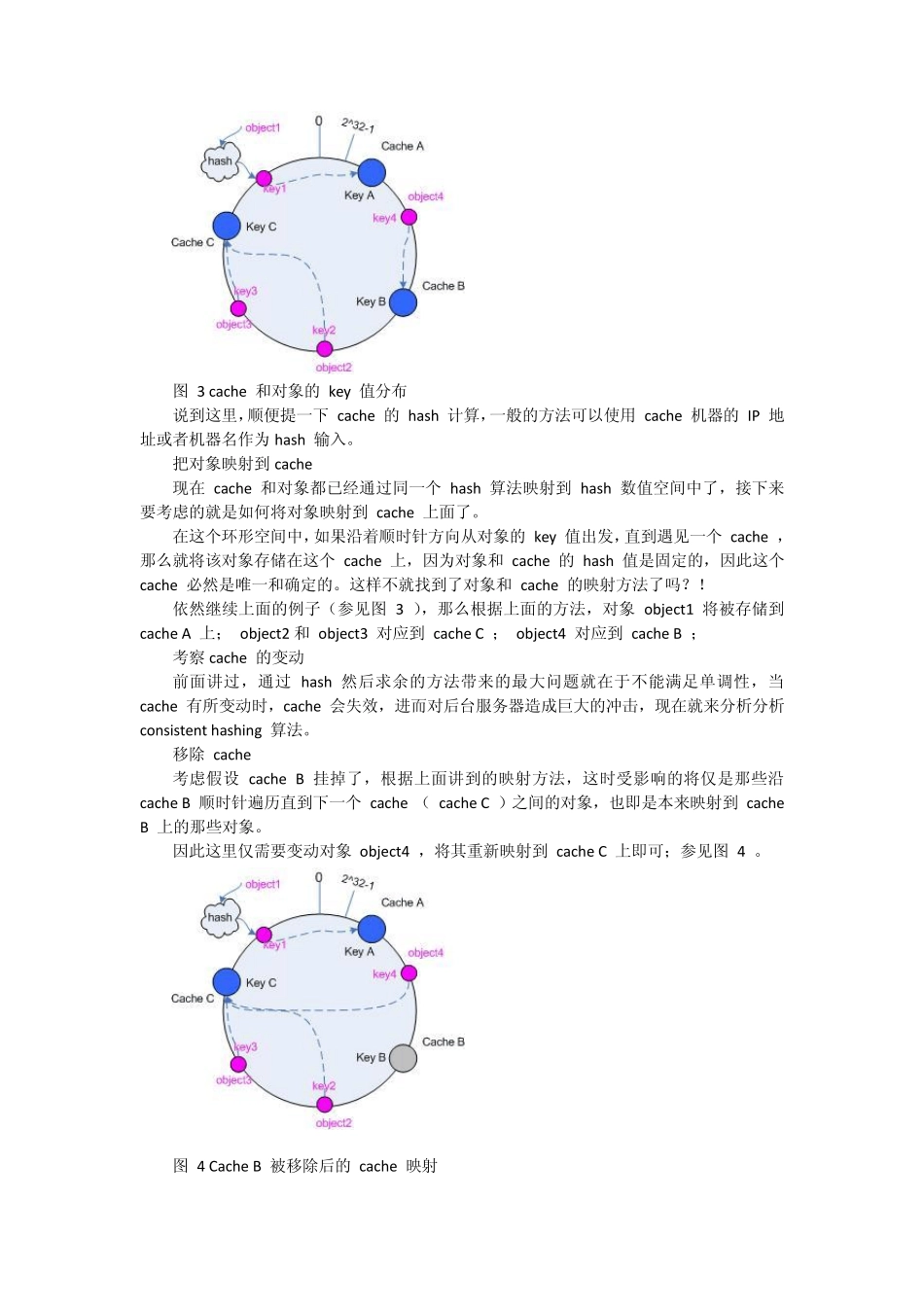
基本场景 比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ; hash(objec