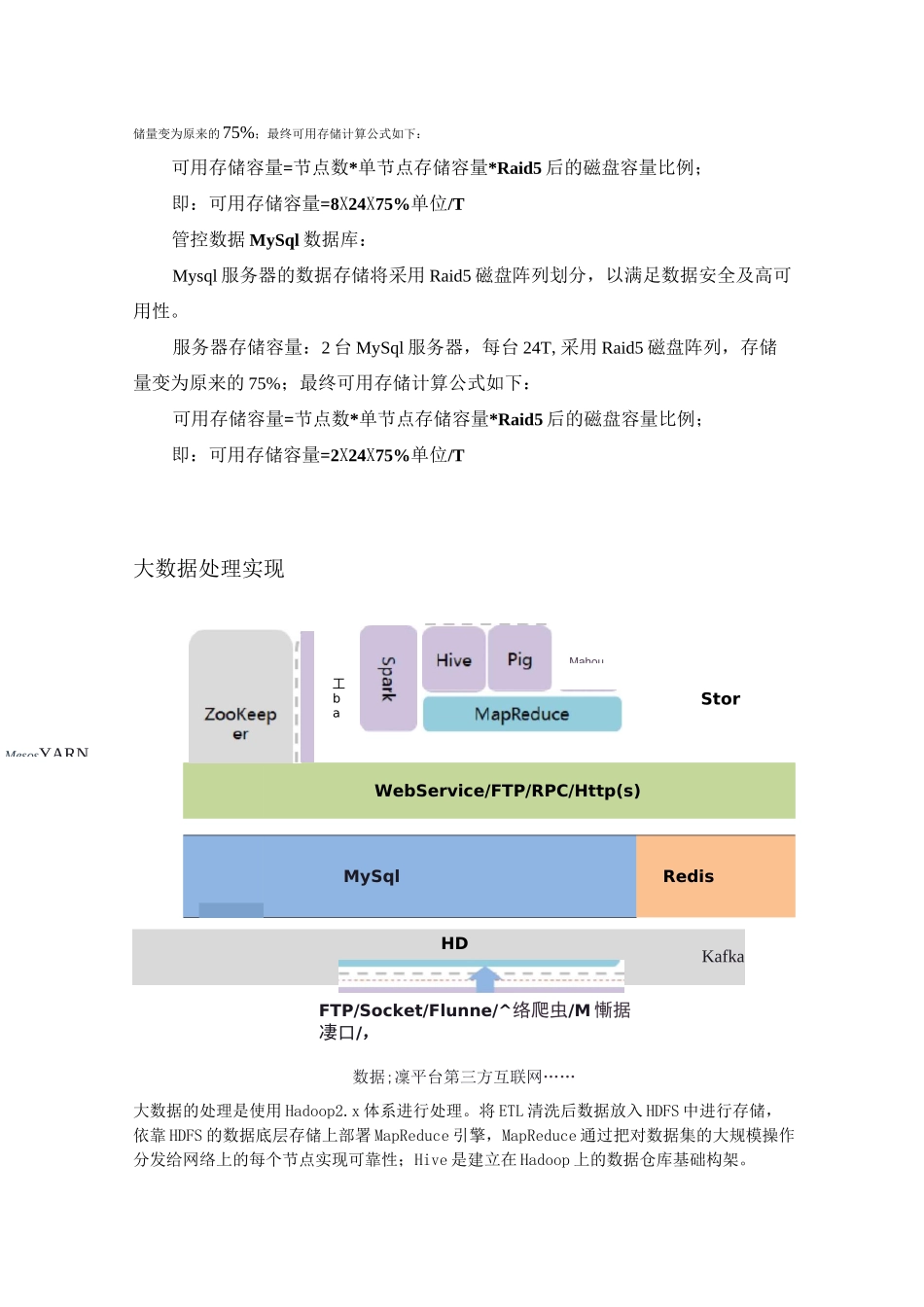
1Hadoop 存储能力详细方案Hadoop 采用 HDFS 作为其底层文件存储方式
HDFS 是分布式文件系统,适合于存储大数据文件,通过将大数据文件切分成多个小数据文件,并且分散存放在多台 DataNode 服务器,同时提供数据冗余机制保证数据安全
本次 Hadoop 存储节点为:300 台 DataNode 服务节点
存储数据安全及分配机制:采用 3 备份机制保证数据安全,同时为系统保留 10%的临时数据交换空间,当数据量超过集群总容量的 90%时,建议增加节点
存储总容量:300 台数据节点,每个节点 36T 的磁盘容量,除去 10%的临时数据交换空间,同时 HDFS 中一份数据存放着 3 份备份;最终存储容量公式如下可用存储容量=节点数*单节点磁盘容量*(1-临时数据交换空间比例)三 HDFS文件备份数量;即:可用存储容量=300X36X(1-10%)F3=3240T;目录规划:针对不同的数据用途和支撑方式进行存储容量划分,存放在HDFS 中的数据分为接口层,处理层,共享层
接口层主要为原始数据,处理层为存放在 HDFS 中数据经 Hive 映射之后数据,共享层为经数据深度沉淀之后存放在 HBase 中
接口层:总容量*50%处理层:总容量*30%共享层:总容量*20%1
2Storm 存储能力详细方案Storm 流数据处理采用 linux 文件系统作为其存储,数据盘采用 raid5 保证数据安全
存储总容量为:30 台服务器,每台 36T,采用 Raid5 磁盘阵列之后,数据容量为原来的 75%,并建议预留 10%的空间;最终可用存储计算公式如下:可用存储容量=节点数*单节点磁盘容量*Raid5 后的磁盘容量比例*(1-临时数据交换空间比例);即:可用存储容量=30X36X75%X(1-10%)=729T;1