2011 土地信息技术 1 1 空间聚类的内涵理解 1
1 定义 空间聚类作为聚类分析的一个研究方向,是指将空间数据集中的对象分成由相似对象组成的类
同类中的对象间具有较高的相似度,而不同类中的对象间差异较大[3]
作为一种无监督的学习方法,空间聚类不需要任何先验知识
这是聚类的基本思想,因此空间聚类也是要满足这个基本思想
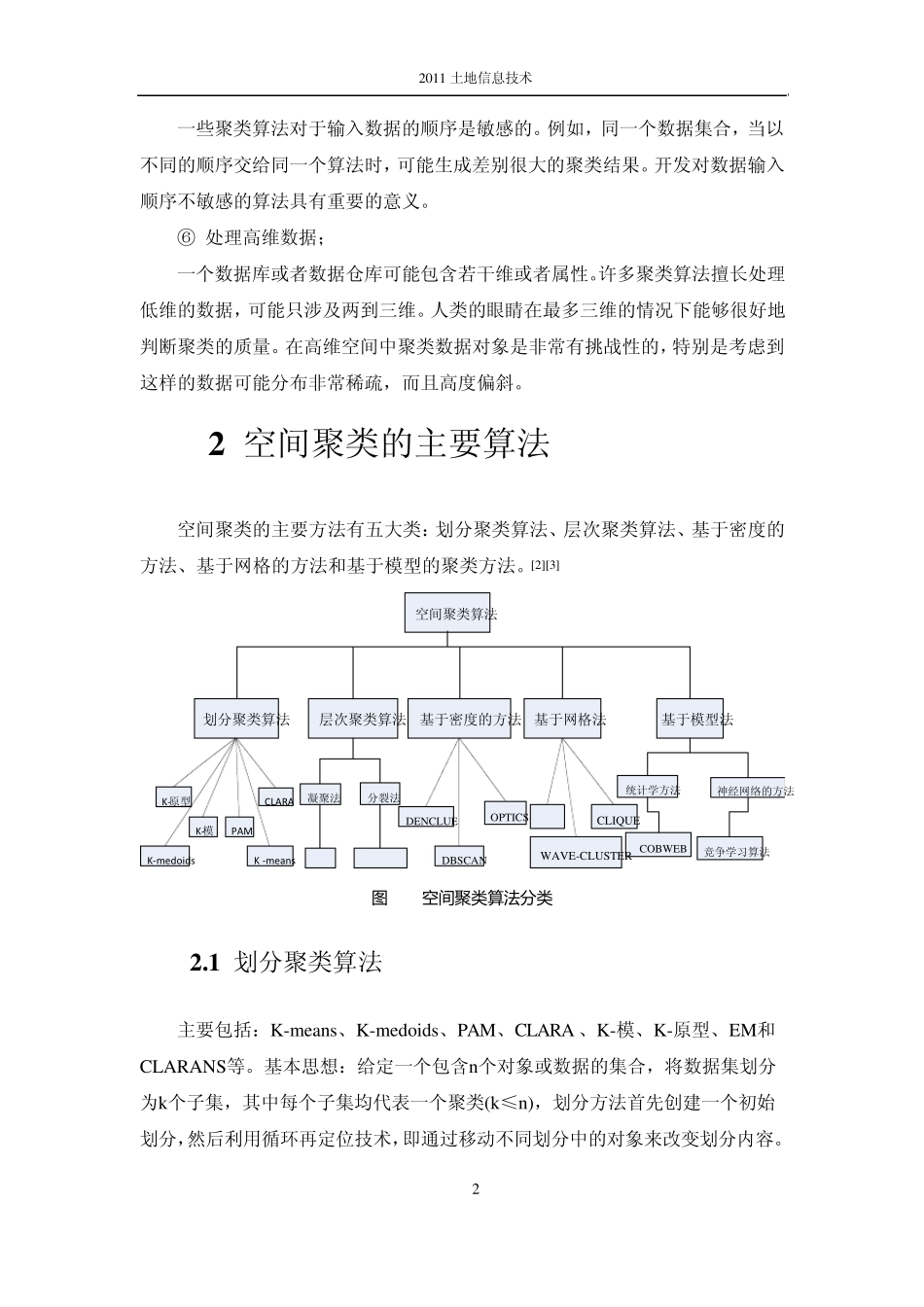
2 对空间数据聚类的要求[2][5][6] ① 可伸缩性; 许多聚类算法在小于 200 个数据对象的小数据集合上工作得很好;但是,一个大规模数据库可能包含几百万个对象,在这样的大数据集合样本上进行聚类可能会导致有偏的结果
我们需要具有高度可伸缩性的聚类算法
② 发现任意形状的聚类; 许多聚类算法基于欧几里得或者曼哈顿距离度量来决定聚类
基于这样的距离度量的算法趋向于发现具有相近尺度和密度的球状簇
但是,一个簇可能是任意形状的
提出能发现任意形状簇的算法是很重要的
(虽然聚类分析属于非监督学习方法,但在某些情况下一些基本的客观规律也会或多或少指示聚类分析的结果) ③ 用于决定输入参数的领域知识最小化; 许多聚类算法在聚类分析中要求用户输入一定的参数,例如希望产生的簇的数目
聚类结果对于输入参数十分敏感
参数通常很难确定,特别是对于包含高维对象的数据集来说
这样不仅加重了用户的负担,也使得聚类的质量难以控制
④ 对噪声数据不敏感; 绝大多数现实中的数据库都包含了孤立点,缺失,或者错误的数据
一些聚类算法对于这样的数据敏感,可能导致低质量的聚类结果
⑤ 对于输入记录的顺序不敏感; 2011 土地信息技术 2 一些聚类算法对于输入数据的顺序是敏感的
例如,同一个数据集合,当以不同的顺序交给同一个算法时,可能生成差别很大的聚类结果
开发对数据输入顺序不敏感的算法具有重要的意义
⑥ 处理高维数据; 一个数据库或者数据仓库可能包含若干维或者属性