通过SQLServer数据仓库查看数据收集组发布日期:[10-01-1110:53:46]点击次数:[4]在此实验中,您将查看系统支持的数据收集类型和收集计划,并配置其属性
通过管理数据仓库向导查看系统收集组及其状态管理数据仓库配置完成后,向导不仅仅会创建数据库(即ManagementDW),同时还将自动启动SQLServerAgent作业来收集并更新系统数据收集组(1)在CHICAGO\SQLDEV01实例中返回ObjectExplorer并依次展开Management,DataCollection,SystemDataCollectionSets
此时可以看到三种系统数据收集组:DiskUsage,QueryStatistics,以及ServerActivity
(2)右键点击DiskUsage然后点击Properties
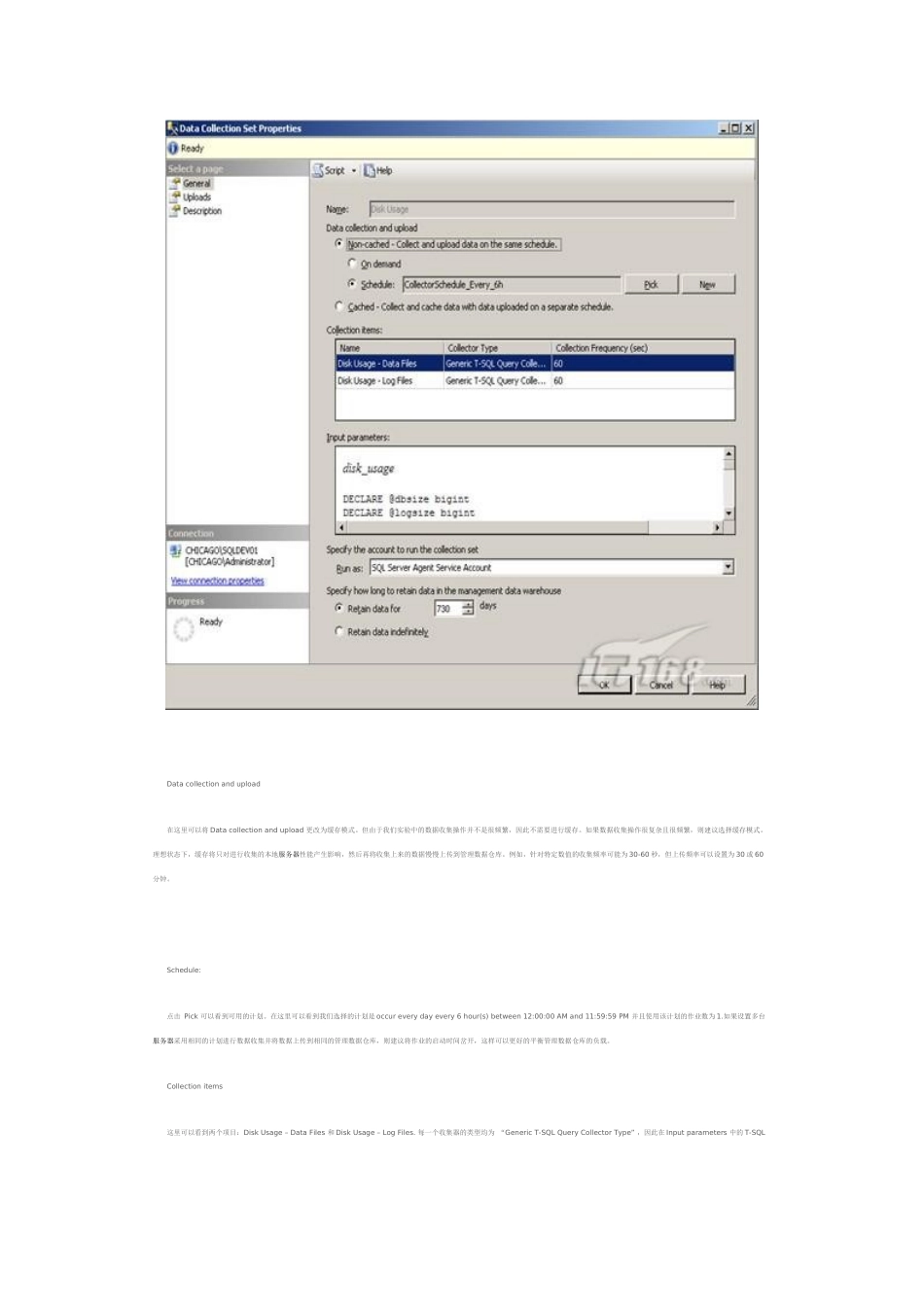
DiskUsage统计数据的完整属性将通过三个选项卡显示,即General,Uploads以及Description
点击Description选项卡可以看到:Collectsdataaboutdiskandlogusageforalldatabases
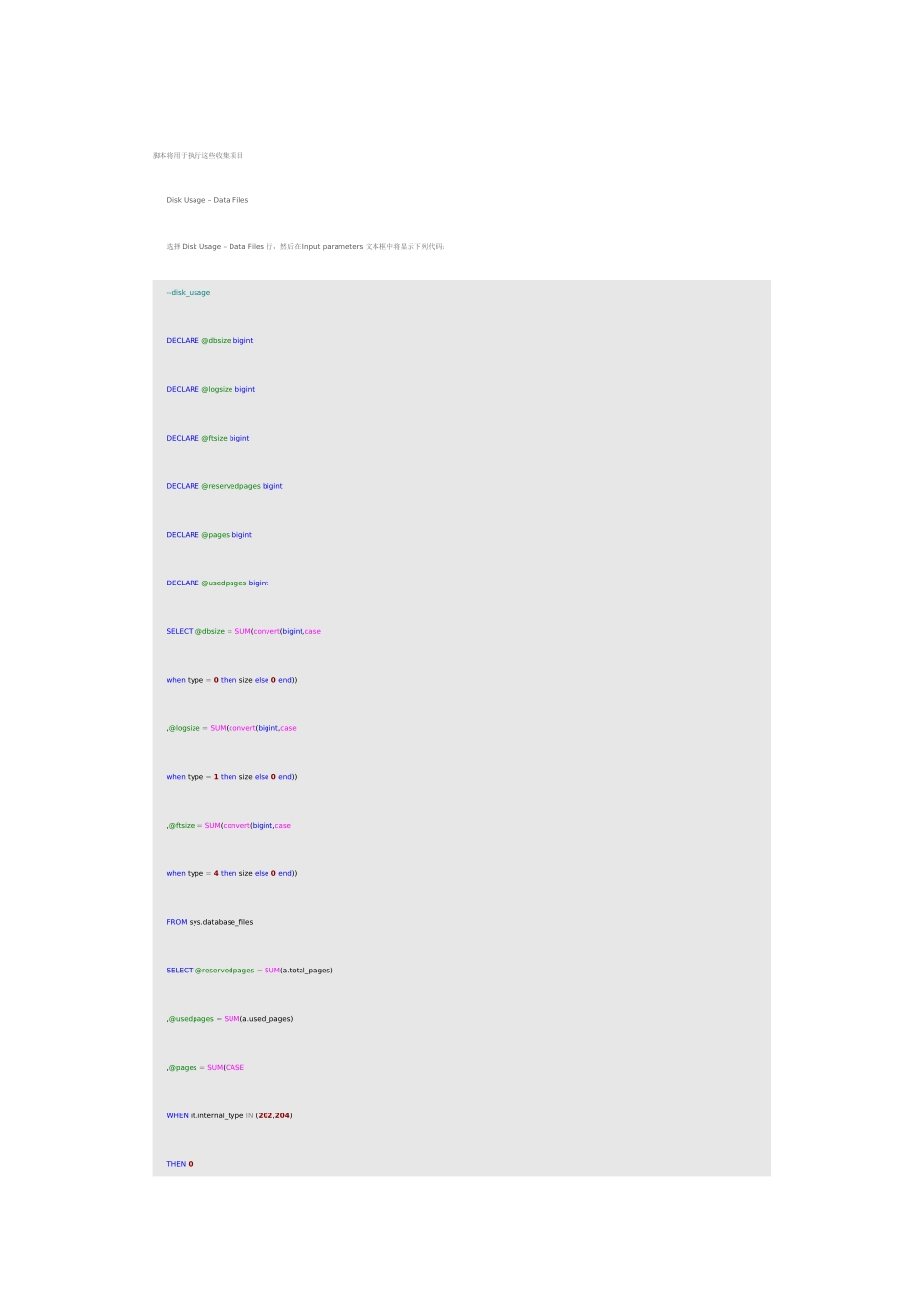
此描述信息并不是很详细,但可以让我们快速了解到磁盘使用的统计信息;这些信息针对实例中的所有数据库的数据文件和日志文件
(3)点击Uploads选项卡可以看到所有信息均为灰色,因为这些特殊的数据集都采用非缓存模式收集
在非缓存模式中数据的收集和上传通过相同的代理作业进行处理
因此Uploads选项卡中的信息对于此收集组来说没有实际意义
非缓存模式对于相对负载较轻或数据集收集操作不是很频繁的情况下很适用(4)最后,点击General选项卡,可以看到该数据收集的特定属性:Datacollectionandupload在这里可以将Datacollectionandupload更改为缓存模式
但由于我们实