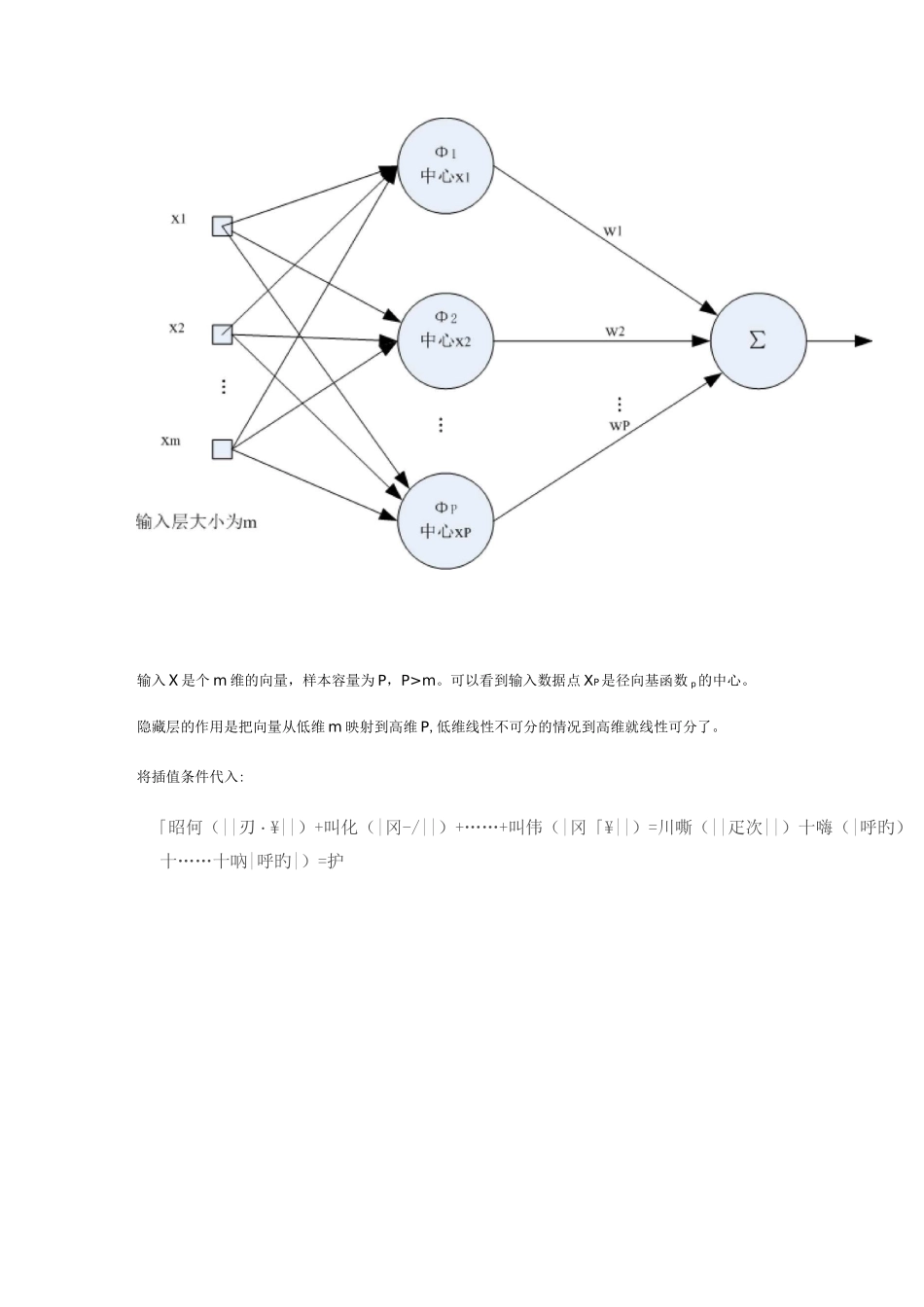
DDDDDDDDDDDDDDCMACDDDDBDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDPDRBFDDDDDDD+叫伟(11DDDDDDDDDRBFDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDBPDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDRBFDDDDDDDDDDDDDDDDDDDPDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDD2ODDDDDDDDDDDDDDDDD尸(对=》旳竹(||苗用||)=叭©(||炉屮||)十叫仞(||苗/||)+卩=LDDDDDDRBFDDDDDRBFDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDD输入X是个m维的向量,样本容量为P,P>m
可以看到输入数据点XP是径向基函数p的中心
隐藏层的作用是把向量从低维m映射到高维P,低维线性不可分的情况到高维就线性可分了
将插值条件代入:「昭何(||刃・¥||)+叫化(|冈-/||)+……+叫伟(|冈「¥||)=川嘶(||疋次||)十嗨(|呼旳)十……十吶|呼旳|)=护n^-xj||)+iv2^2(n^-r||)+……+%竹(II枣「糾|)二岀写成向量的形式为叫,显然是个规模这P对称矩阵,且与X的维度无关,当可逆时,对于一大类函数,当输入的X各不相同时,就是可逆的
下面的几个函数就属于这一大类函数:1)Gauss(高斯)函数爭(F)=E®()2(7-2