数据仓库与数据挖掘学习要点第一章引言1、数据挖掘的概念,即什么是数据挖掘
数据挖掘--从大量数据中寻找其规律的技术,是统计学、数据库技术和人工智能技术的综合
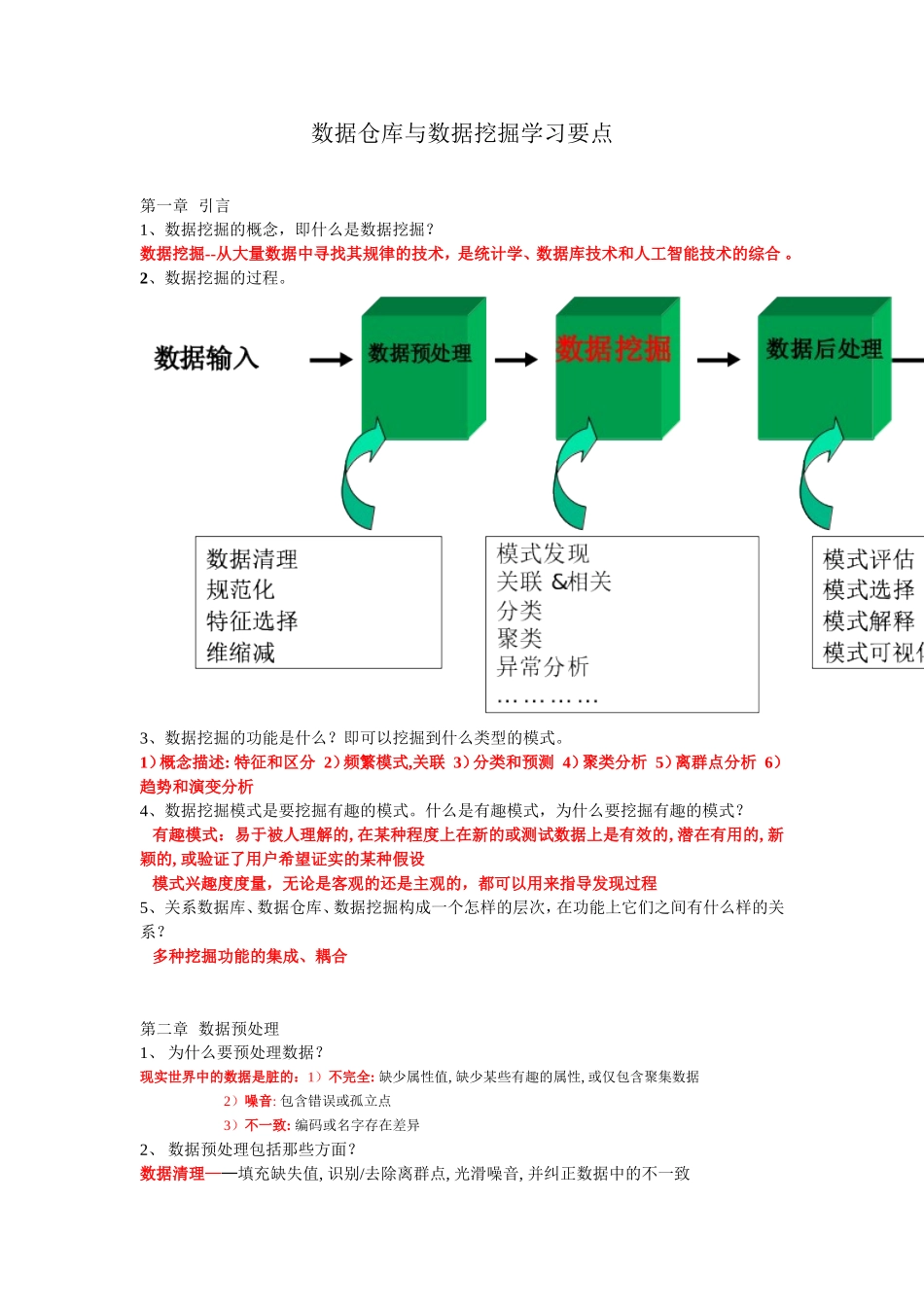
2、数据挖掘的过程
3、数据挖掘的功能是什么
即可以挖掘到什么类型的模式
1)概念描述:特征和区分2)频繁模式,关联3)分类和预测4)聚类分析5)离群点分析6)趋势和演变分析4、数据挖掘模式是要挖掘有趣的模式
什么是有趣模式,为什么要挖掘有趣的模式
有趣模式:易于被人理解的,在某种程度上在新的或测试数据上是有效的,潜在有用的,新颖的,或验证了用户希望证实的某种假设模式兴趣度度量,无论是客观的还是主观的,都可以用来指导发现过程5、关系数据库、数据仓库、数据挖掘构成一个怎样的层次,在功能上它们之间有什么样的关系
多种挖掘功能的集成、耦合第二章数据预处理1、为什么要预处理数据
现实世界中的数据是脏的:1)不完全:缺少属性值,缺少某些有趣的属性,或仅包含聚集数据2)噪音:包含错误或孤立点3)不一致:编码或名字存在差异2、数据预处理包括那些方面
数据清理——填充缺失值,识别/去除离群点,光滑噪音,并纠正数据中的不一致数据集成——多个数据库,数据立方体,或文件的集成数据变换——规范化和聚集数据归约——得到数据的归约表示,它小得多,但产生相同或类似的分析结果:维度规约、数值规约、数据压缩数据离散化和概念分层3、数据清理的概念,数据清理包括那些方面
数据清理——填充缺失值,识别/去除离群点,光滑噪音,并纠正数据中的不一致数据清理包括缺失值、噪声数据、不一致性、偏差检测和数据交换4、数据集成和变换的概念
数据集成——多个数据库,数据立方体,或文件的集成数据变换——规范化和聚集5、数据规约的概念,数据规约包括那些方面
数据归约——得到数据的归约表示,它小得多,但产生相同或类似的分析结果:维度规约、数值规约、数据压缩数据规约包括数据立方体聚