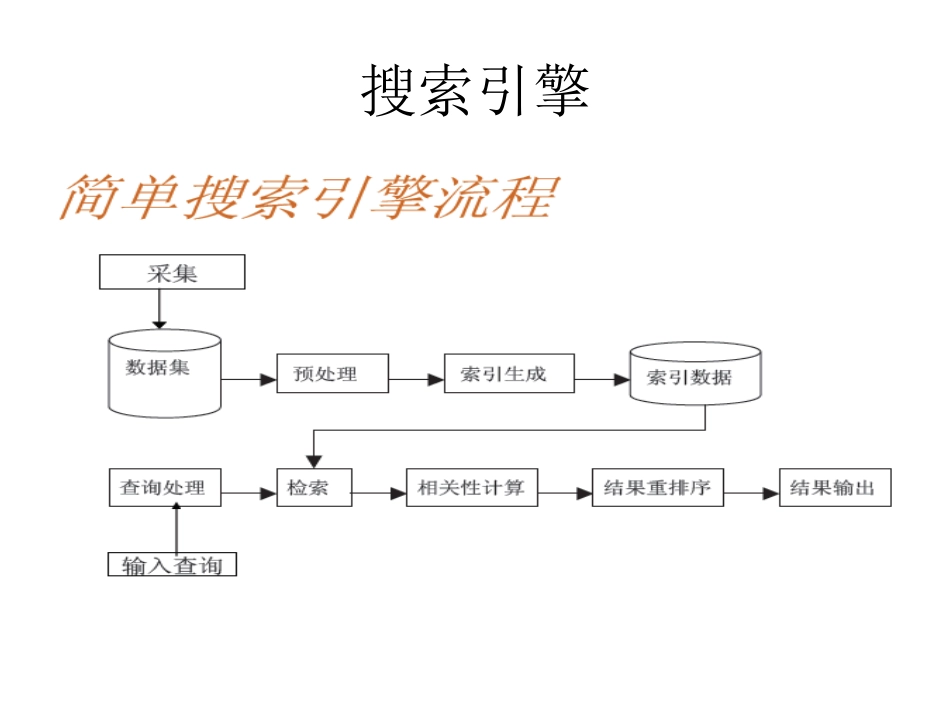
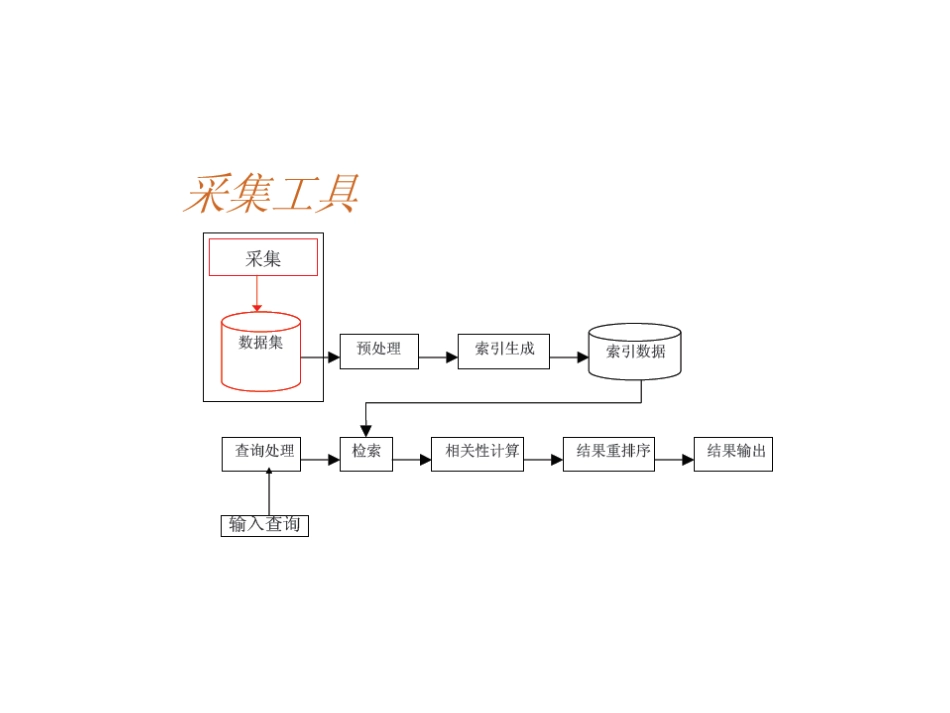
搜索引擎Heritrix介绍•在一个搜索引擎的开发过程中,使用一个合适的爬虫来获得所需要的网页信息是第一步,这一步是整个系统成功的基础
•Heritrix是一个纯由Java开发的、开源的Web网络爬虫,用户可以使用它从网络上抓取想要的资源
•它来自于www
archive
•Heritrix最出色之处在于它的可扩展性,开发者可以扩展它的各个组件,来实现自己的抓取逻辑
Java开源Web爬虫1•Heritrix–Heritrix是一个开源,可扩展的web爬虫项目
Heritrix设计成严格按照robots
txt文件的排除指示和METArobots标签
•WebSPHINX–WebSPHINX是一个Java类包和Web爬虫的交互式开发环境
Web爬虫(也叫作机器人或蜘蛛)是可以自动浏览与处理Web页面的程序
WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包
•WebLech–WebLech是一个功能强大的Web站点下载与镜像工具
它支持按功能需求来下载web站点并能够尽可能模仿标准Web浏览器的行为
WebLech有一个功能控制台并采用多线程操作
•Arale–Arale主要为个人使用而设计,而没有像其它爬虫一样是关注于页面索引
Arale能够下载整个web站点或来自web站点的某些资源
Arale还能够把动态页面映射成静态页面
•J-Spider–J-Spider:是一个完全可配置和定制的WebSpider引擎
你可以利用它来检查网站的错误(内在的服务器错误等),网站内外部链接检查,分析网站的结构(可创建一个网站地图),下载整个Web站点,你还可以写一个JSpider插件来扩展你所需要的功能
•spindle–spindle是一个构建在Lucene工具包之上的Web索引/搜索工具
它包括一个用于创建索引的HTTPspider和一个用于搜索这些索引