搜索引擎中文分词原理与实现因为中文文本中,词和词之间不像英文一样存在边界,所以中文分词是一个专业处理中文信息的搜索引擎首先面对的问题,需要靠程序来切分出词
一、Lucene中的中文分词Lucene在中处理中文的常用方法有三种,以“咬死猎人的狗”为例说明之:单字:【咬】【死】【猎】【人】【的】【狗】二元覆盖:【咬死】【死猎】【猎人】【人的】【的狗】分词:【咬】【死】【猎人】【的】【狗】Lucene中的StandardTokenizer采用单子分词方式,CJKTokenizer采用二元覆盖方式
1、Lucene切分原理Lucene中负责语言处理的部分在org
apache
lucene
analysis包,其中,TokenStream类用来进行基本的分词工作,Analyzer类是TokenStream的包装类,负责整个解析工作,Analyzer类接收整段文本,解析出有意义的词语
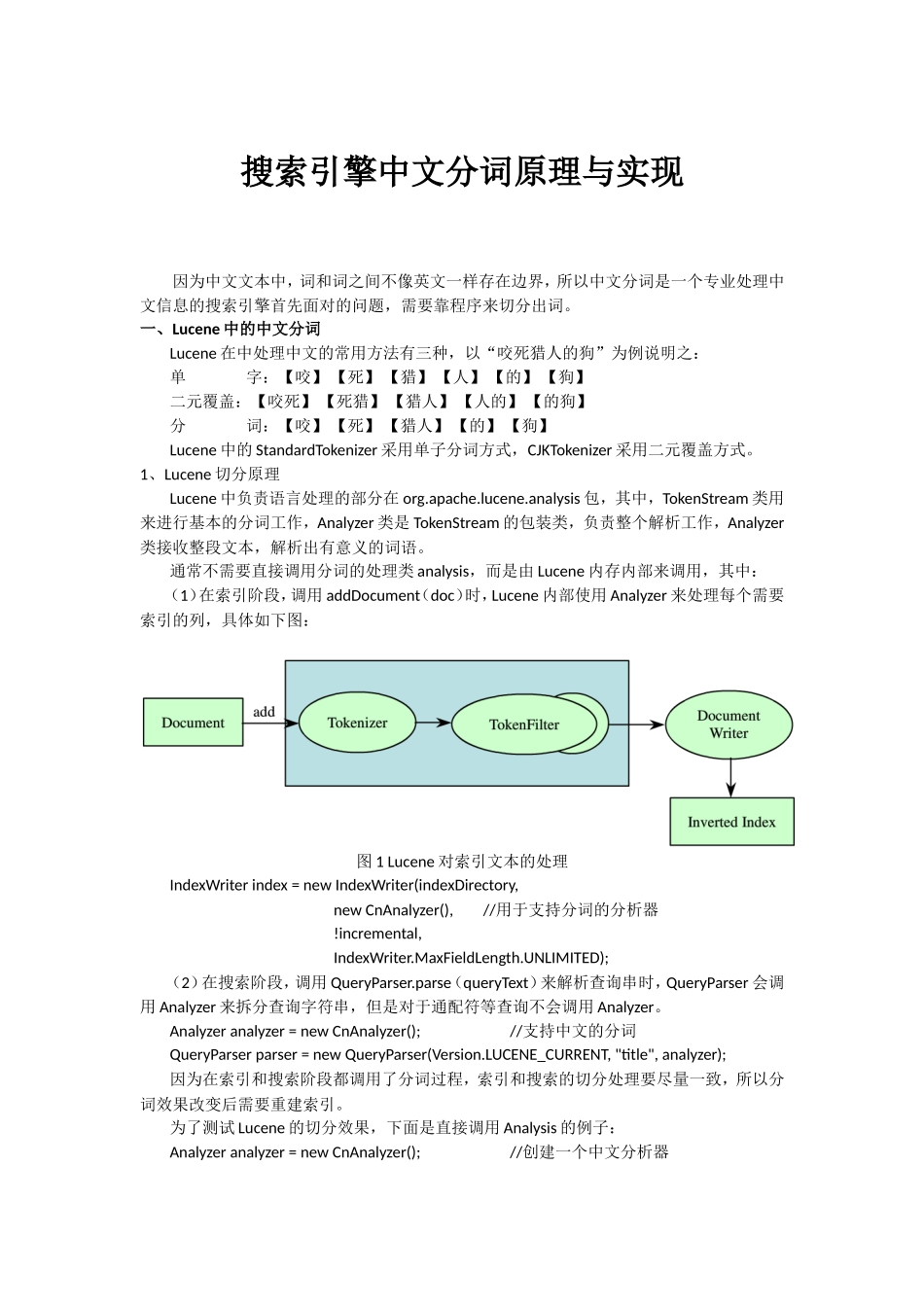
通常不需要直接调用分词的处理类analysis,而是由Lucene内存内部来调用,其中:(1)在索引阶段,调用addDocument(doc)时,Lucene内部使用Analyzer来处理每个需要索引的列,具体如下图:图1Lucene对索引文本的处理IndexWriterindex=newIndexWriter(indexDirectory,newCnAnalyzer(),//用于支持分词的分析器
incremental,IndexWriter
MaxFieldLength
UNLIMITED);(2)在搜索阶段,调用QueryParser
parse(queryText)来解析查询串时,QueryParser会调用Analyzer来拆分查询字符串,但是对于通配符等查询不会调用Analyzer
Analyzeranalyzer=newCnAnalyzer();//支持中文的分词QueryParserpa