问题二:上述先用diff命令做了双重差分PSM,又进行了检验,发现处理组和控制组间协变量的均值在匹配后不存在显著差异
请问老师,第一步的命令做的PSM-DID是不是已经在得分匹配后的双重差分
367的处理效应是不是可以理解为挑选出来的样本的双重差分结果
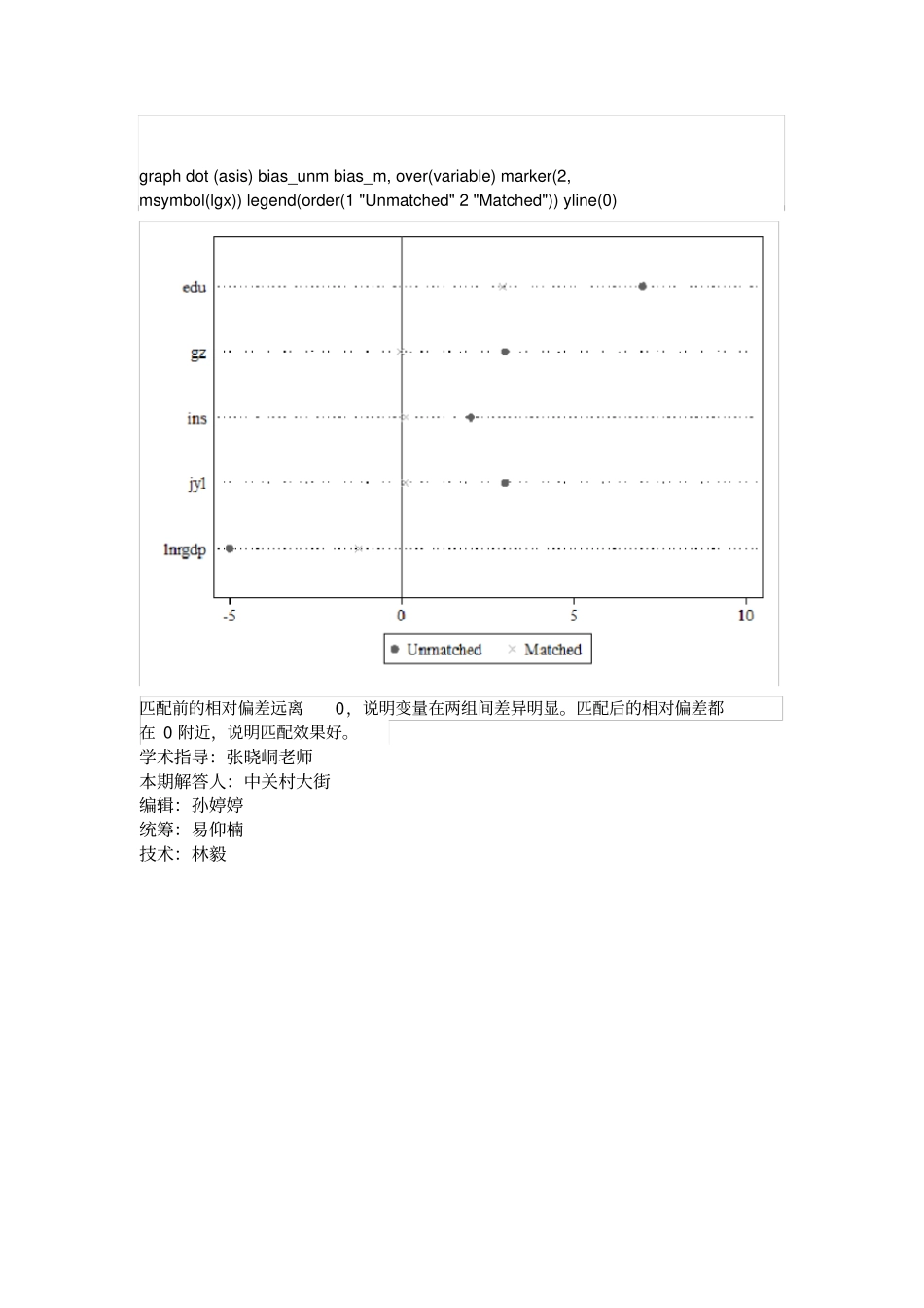
请问使用什么命令才可得到下图
回复二:是的,第一步的命令做出的0
367的处理效应已经是PSM-DID的最终结果
这幅图画的应该是匹配前后主要变量在处理组和控制组之间的相对偏差
例如,匹配之后,变量jyl在处理组中的均值是96
993,在控制组中的均值是96
908,所以该变量的相对偏差是0
0877%=(96
993-96
908)/96
908*100%
匹配之前,相对偏差就会大一些
下面是一个示例数据:其中,variable记录了主要变量的名字,bias_m计算了各变量在匹配之后的相对偏差(根据上面的平衡性检验结果计算),bias_unm计算了各变量在匹配之前的相对偏差(提问者未提供相关信息,所以这个变量的数据只是随意给定的数值)
运行下述命令后,可得到下图
graphdot(asis)bias_unmbias_m,over(variable)marker(2,msymbol(lgx))legend(order(1"Unmatched"2"Matched"))yline(0)匹配前的相对偏差远离0,说明变量在两组间差异明显
匹配后的相对偏差都在0附近,说明匹配效果好
学术指导:张晓峒老师本期解答人:中关村大街编辑:孙婷婷统筹:易仰楠技术:林毅