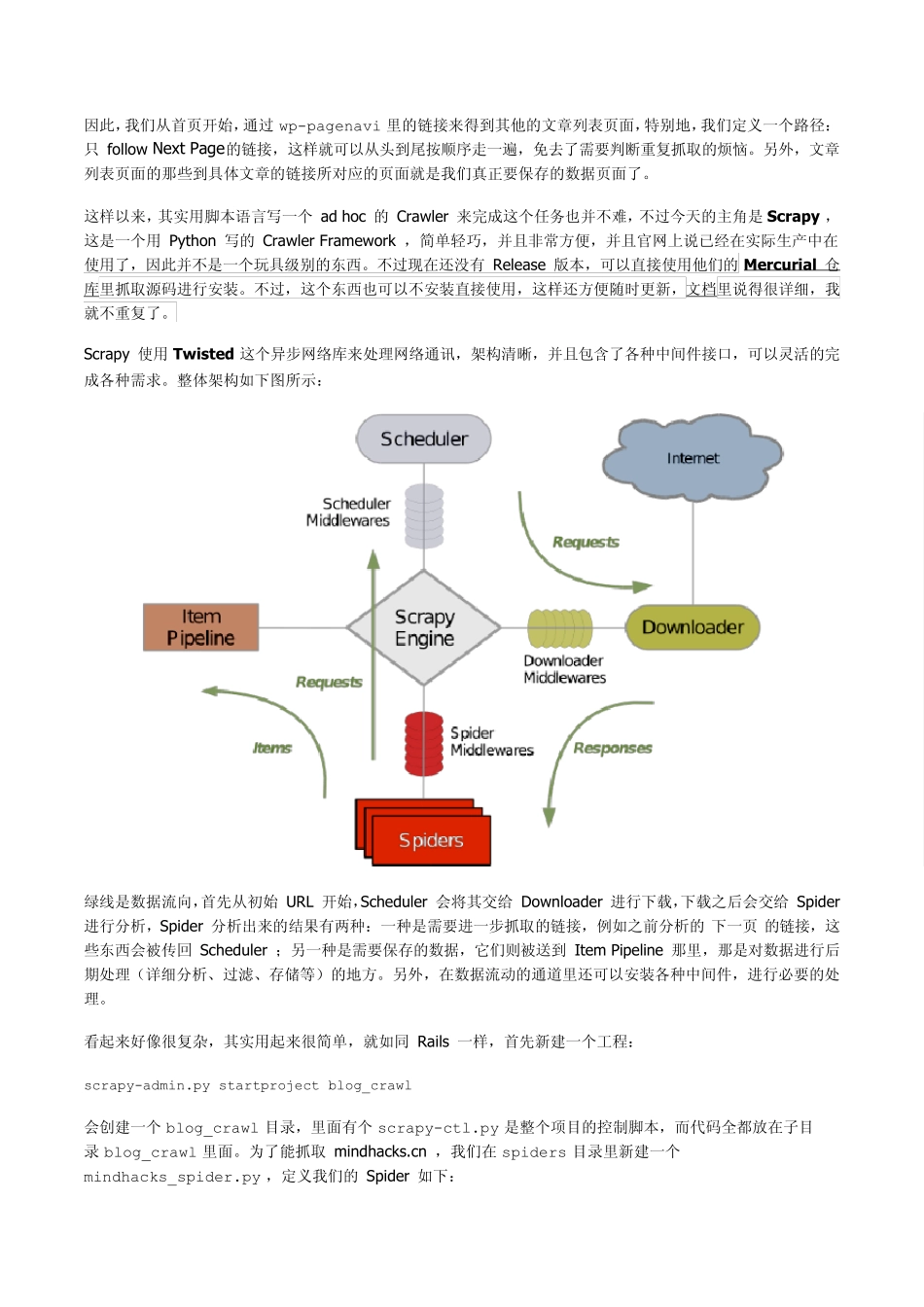
Scrapy 轻松定制网络爬虫 by pluskid, on 2009-08-14 网络爬虫(Web Crawler, Spider)就是一个在网络上乱爬的机器人
当然它通常并不是一个实体的机器人,因为网络本身也是虚拟的东西,所以这个“机器人”其实也就是一段程序,并且它也不是乱爬,而是有一定目的的,并且在爬行的时候会搜集一些信息
例如 Google 就有一大堆爬虫会在 Internet 上搜集网页内容以及它们之间的链接等信息;又比如一些别有用心的爬虫会在 Internet 上搜集诸如 foo@bar
com 或者 foo [at] bar [dot] com 之类的东西
除此之外,还有一些定制的爬虫,专门针对某一个网站,例如前一阵子 JavaEye 的 Robbin 就写了几篇专门对付恶意爬虫的 blog (原文链接似乎已经失效了,就不给了),还有诸如小众软件或者 LinuxToy 这样的网站也经常被整个站点 crawl 下来,换个名字挂出来
其实爬虫从基本原理上来讲很简单,只要能访问网络和分析 Web 页面即可,现在大部分语言都有方便的 Http 客户端库可以抓取 Web 页面,而 HTML 的分析最简单的可以直接用正则表达式来做,因此要做一个最简陋的网络爬虫实际上是一件很简单的事情
不过要实现一个高质量的 spider 却是非常难的
爬虫的两部分,一是下载 Web 页面,有许多问题需要考虑,如何最大程度地利用本地带宽,如何调度针对不同站点的 Web 请求以减轻对方服务器的负担等
一个高性能的 Web Crawler 系统里,DNS 查询也会成为急需优化的瓶颈,另外,还有一些“行规”需要遵循(例如 robots
而获取了网页之后的分析过程也是非常复杂的,Internet 上的东西千奇百怪,各种错误百出的 HTML 页面都有,要想全部分析清楚几乎是不可能的事;另