提及分布式key-value 存储系统, Memcached, Voldemort, Cassandra,包括淘宝最近开源,我们一直在使用的Tair 系统,相信大家都不会觉得陌生
本文会从 Tair 入手,介绍分析一下传统分布式键-值存储系统的原理,架构和使用技术
错误之处,还望大家指正
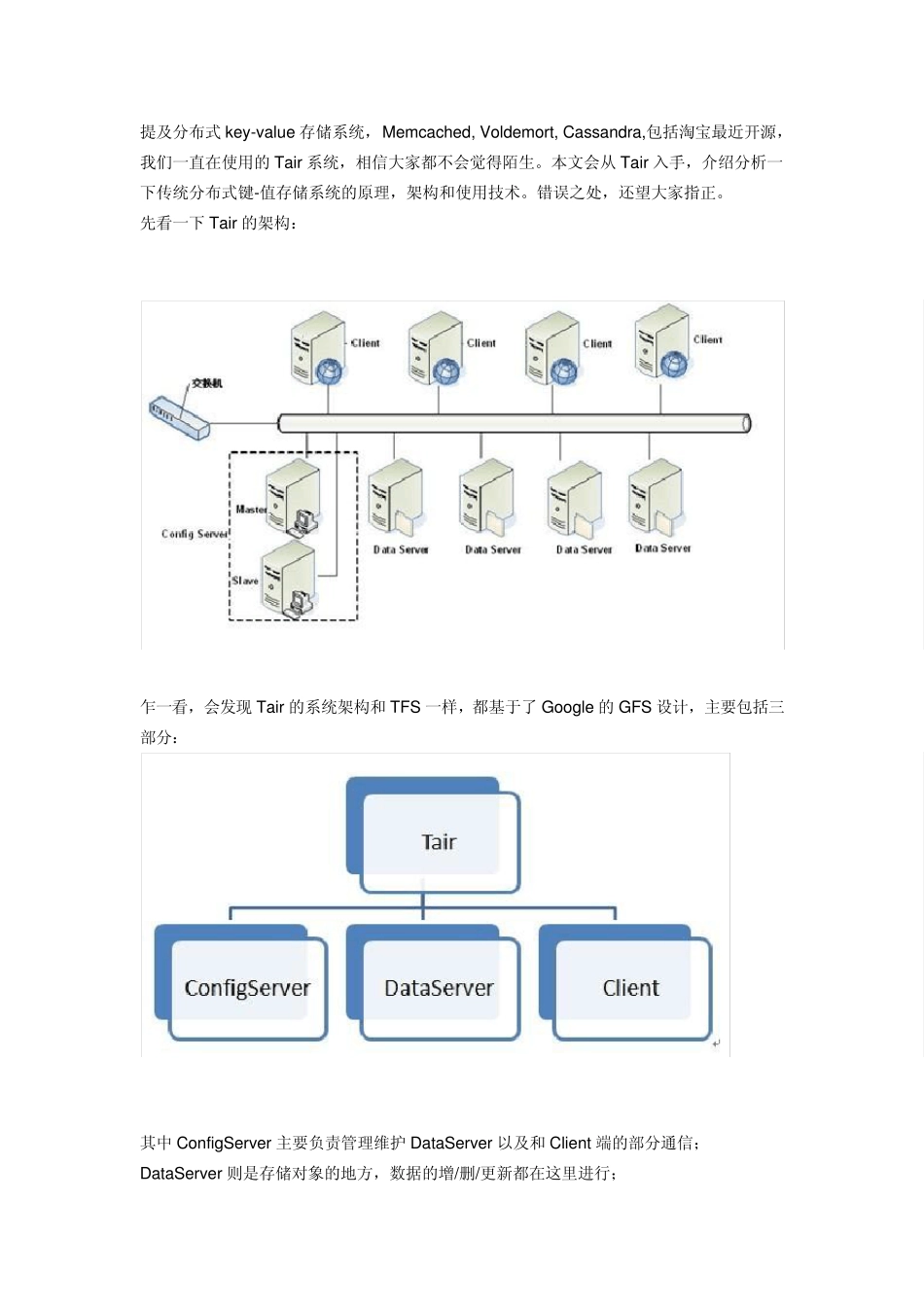
先看一下 Tair 的架构: 乍一看,会发现 Tair 的系统架构和 TFS 一样,都基于了 Google 的GFS 设计,主要包括三部分: 其中 ConfigServer 主要负责管理维护 DataServer 以及和 Client 端的部分通信; DataServer 则是存储对象的地方,数据的增/删/更新都在这里进行; Client 端向服务器请求插入/删除/更新数据; 看完上面的介绍,你可能会有以下几个疑问: 1
configServ er 的真正工作是什么
DataServ er 如何存储数据
Client 端只需要和dataServ er 通信吗
如何实现分布式
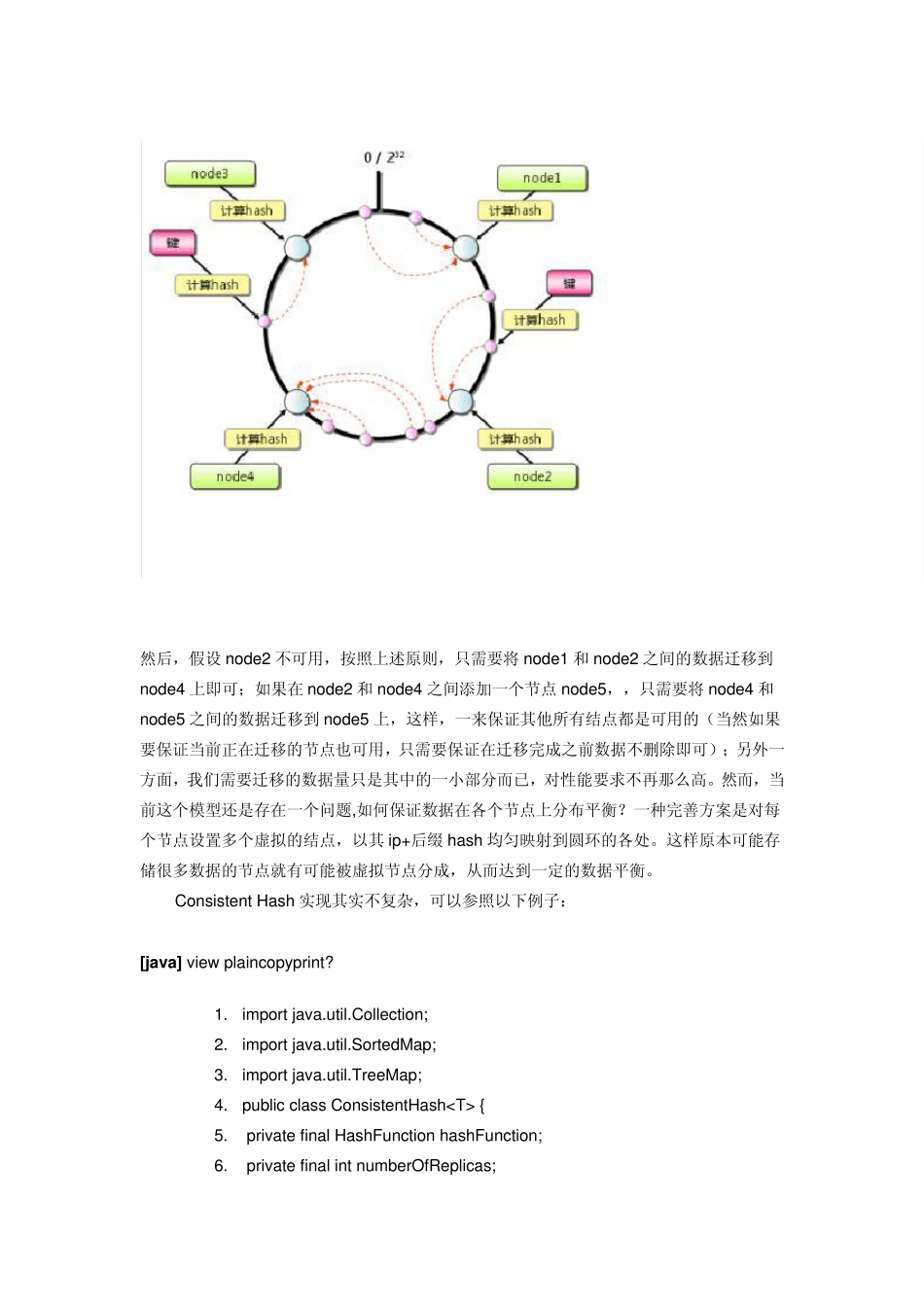
关于上述第四点如何实现分布式键-值存储系统,我们又要从分布式系统CAP 要求出发:数据一致性,系统可用性,系统分区宽容度(说白了就是如何解决分布式下Serv er 端机器的增减和容错问题)
这几个问题才是分布式应用中最棘手最重要的问题
接下来,依据个人的理解,结合 Tair 相关知识,对上述问题做一下介绍
首先,tair 中的configServ er 在物理上是以Master-Slav er 形式部署,作用大家都很清楚,在 Master 不可用或者宕机的时候,slav er 转为 master 对外提供服务
那么是不是configServ er 不能对外部提供就说明所有的客户端都不再可用
答案是否定的,因为configServ er 在 tair 中扮演的是一个非常轻量级的角色,如何理