1 概述 随着海量数据问题的出现,海量管理能力,多类型,变化快,高可用性,低成本,高端可扩展性等需求给企业数据战略带来了巨大的挑战
企业数据仓库、数据中心的技术选型变得尤其重要
所以在选型之前,有必要对目前市场上各种大数据量的解决方案进行分析
2 主流分布式并行处理数据库产品介绍 2
1 Greenplum 2
1 基础架构 Greenplu m 是基于 Hadoop 的一款分布式数据库产品,在处理海量数据方面相比传统数据库有着较大的优势
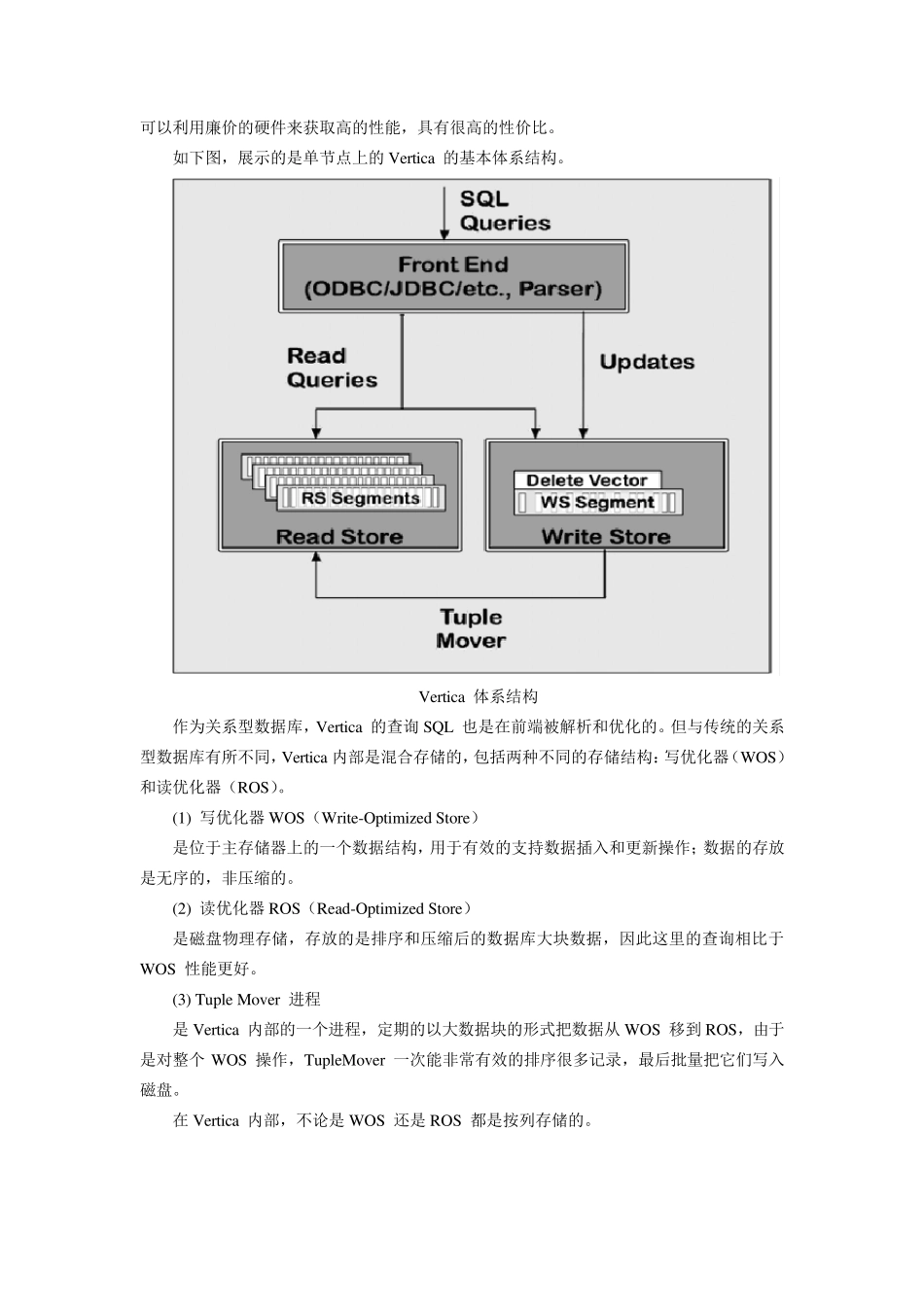
Greenplu m 整体架构如下图: 数据库由 Master Sev ers 和 Segment Sev ers 通过 Interconnect 互联组成
Master 主机负责:建立与客户端的连接和管理;SQL 的解析并形成执行计划;执行计划向 Segment 的分发收集 Segment 的执行结果;Master 不存储业务数据,只存储数据字典
Segment 主机负责:业务数据的存储和存取;用户查询 SQL 的执行
2 主要特性 Greenplu m 整体有如下技术特点: Shared-nothing 架构 Network Interconnect
Master Severs 查询解析、优化、分发 Segment Severs 查询处理、数据存储 External Sources 数据加载 SQL MapReduc
SQL MapReduc海量数据库采用最易于扩展的Shared-nothing 架构,每个节点都有自己的操作系统、数据库、硬件资源,节点之间通过网络来通信
基于gNet Softw are Interconnect 数据库的内部通信通过基于超级计算的“软件 Sw itch”内部连接层,基于通用的gNet (GigE, 10GigE) NICs/sw i