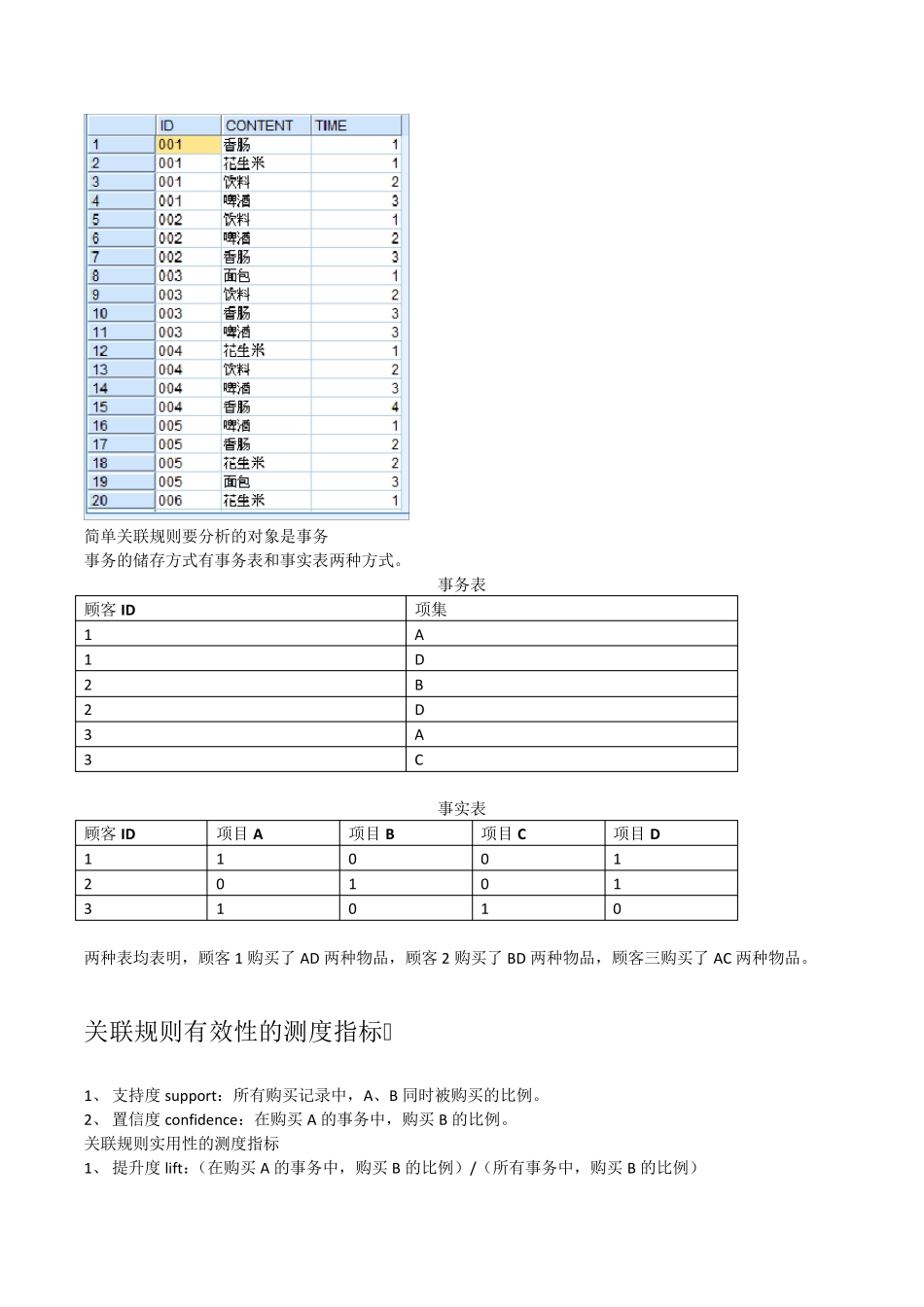
关联分析(笔记) 事物之间的关联关系包括:简单关联关系、序列关联关系
简单关联规则:属于无指导学习方法,不直接用于分类预测,只揭示事物内部的结构
Spss modeler 提供了 APriori、GRI、Carma 等经典算法
APriori 和 Carma 属于同类算法
序列关联:关联具有前后顺序,通常与时间有关
SPSS Modeler 提供了 sequence 算法; 数据格式如下:按照事务表存储,同事需要时间变量
关联关系简单关联关系序列关联关系Apriori只能处理分类变量数据可以是按事务表存储,亦可事实表存储
算法为提高关联规则的产生效率而设计GRI不但可以处理分类变量,前项也可是数值变量数据只能按照事实表存储采用深度优先搜索策略实现算法 简单关联规则要分析的对象是事务 事务的储存方式有事务表和事实表两种方式
事务表 顾客ID 项集 1 A 1 D 2 B 2 D 3 A 3 C 事实表 顾客ID 项目A 项目B 项目C 项目D 1 1 0 0 1 2 0 1 0 1 3 1 0 1 0 两种表均表明,顾客1 购买了AD 两种物品,顾客2 购买了BD 两种物品,顾客三购买了AC 两种物品
关联规则有效性的测度指标 1、 支持度su pport:所有购买记录中,A、B 同时被购买的比例
2、 置信度confidence:在购买A 的事务中,购买B 的比例
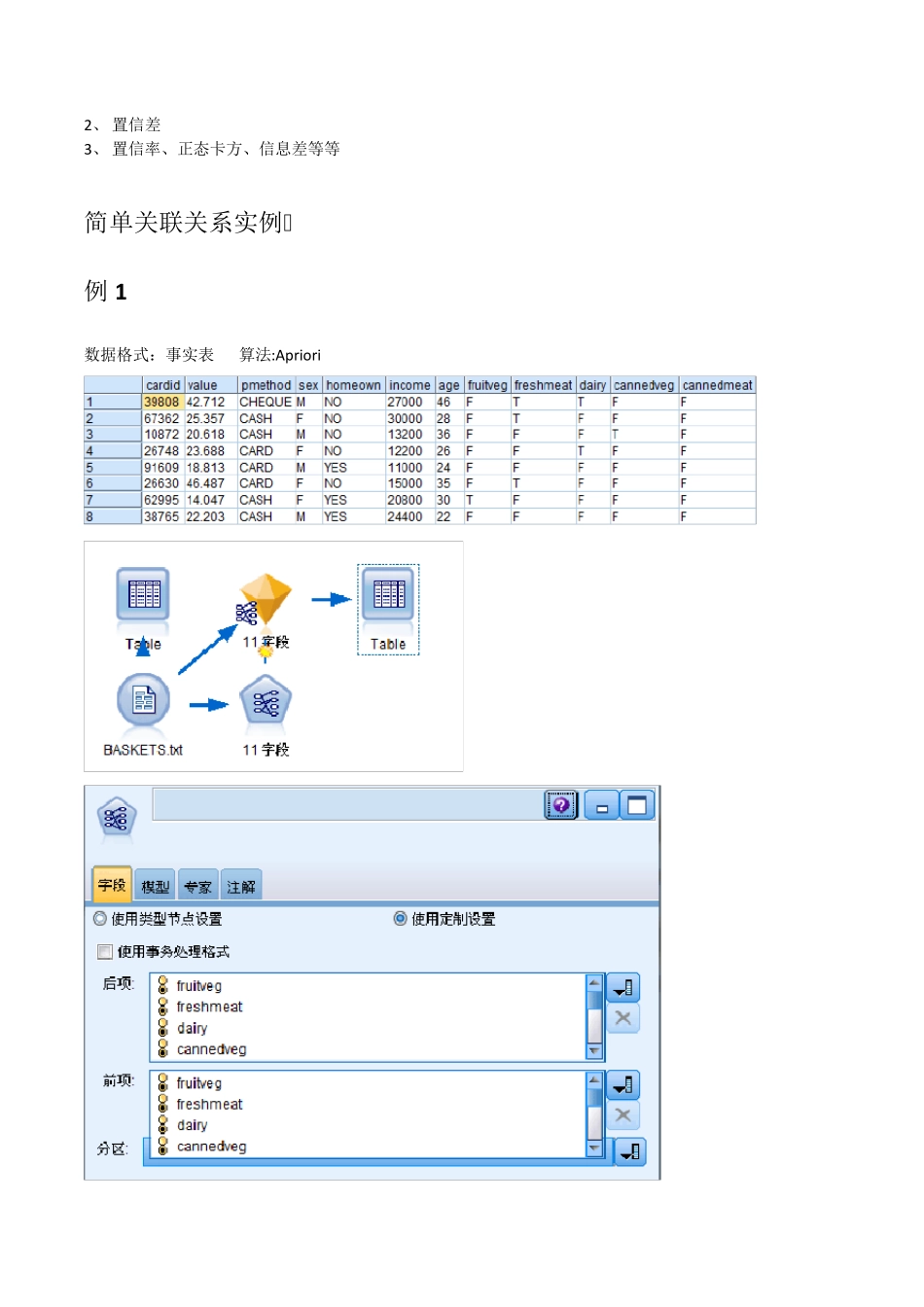
关联规则实用性的测度指标 1、 提升度lift:(在购买A 的事务中,购买B 的比例)/(所有事务中,购买B 的比例) 2、 置信差 3、 置信率、正态卡方、信息差等等 简单关联关系实例 例 1 数据格式:事实表 算法:Apriori 所有购买项目均选入前项antecedent 和后项consequent
输出结果的最低支持度是10%;本例设定的划分频繁项集的标准大于最小支持度10%