3 1 5Deep Sparse Rectifier Neural Netw orksXavier GlorotAntoine BordesYoshua BengioDIRO, Universit´e de Montr´ealMontr´eal, QC, Canadaglorotxa@iro
umontreal
caHeudiasyc, UMR CNRS 6599UTC, Compi`egne, FranceandDIRO, Universit´e de Montr´ealMontr´eal, QC, Canadaantoine
bordes@hds
frDIRO, Universit´e de Montr´ealMontr´eal, QC, Canadabengioy@iro
umontreal
caAbstractWhile logistic sigmoid neurons are more bi-ologically plausible than hyperbolic tangentneurons, the latter work better for train-ing multi-layer neural networks
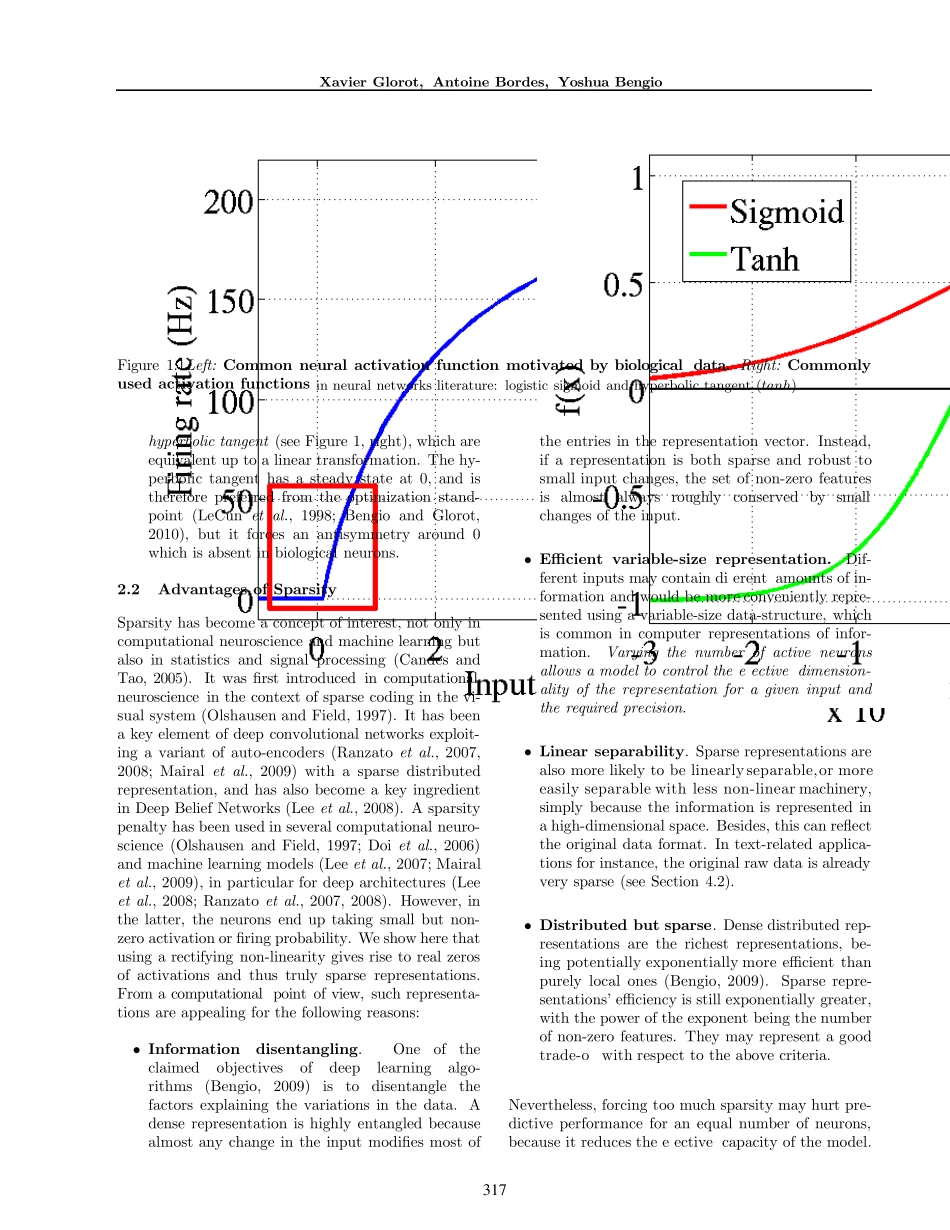
This pa-per shows that rectifying neurons are aneven better model of biological neurons andyield equal or better performance than hy-perbolic tangent networks in spite of thehard non-linearity and non-differentiabilityat zero, creating sparse representations withtrue zer