精品文档---下载后可任意编辑1 Hadoop 简介Apache Hadoop 是一款支持数据密集型分布式应用并以 Apache 2
0 许可协议发布的开源软件框架
它支持在商品硬件构建的大型集群上运行的应用程序
Hadoop 是根据 Google 公司发表的 MapReduce 和 Google文件系统的论文自行实现而成
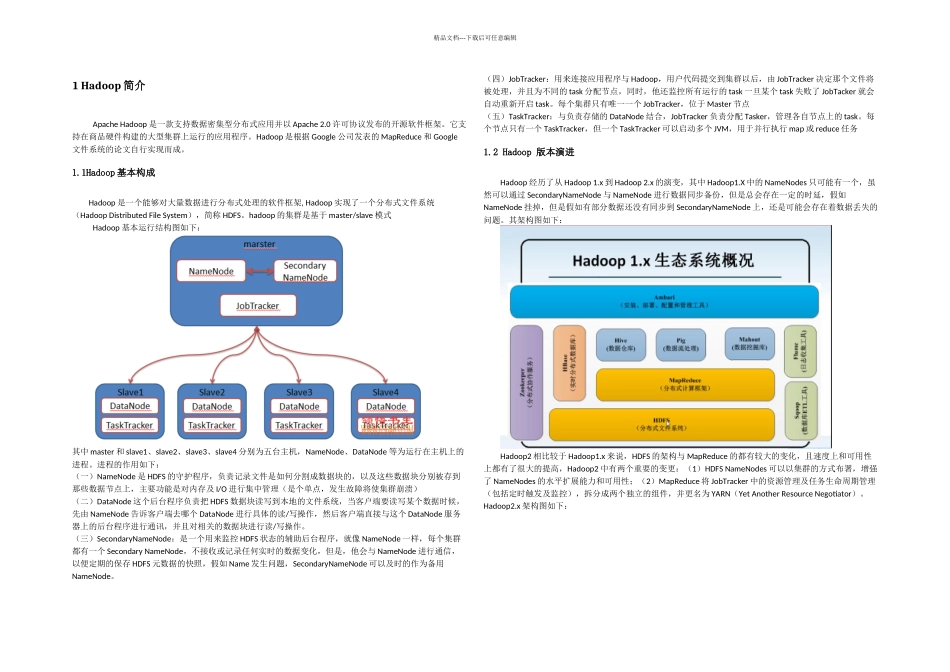
1Hadoop 基本构成Hadoop 是一个能够对大量数据进行分布式处理的软件框架, Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称 HDFS
hadoop 的集群是基于 master/slave 模式Hadoop 基本运行结构图如下:其中 master 和 slave1、slave2、slave3、slave4 分别为五台主机,NameNode、DataNode 等为运行在主机上的进程
进程的作用如下:(一)NameNode 是 HDFS 的守护程序,负责记录文件是如何分割成数据块的,以及这些数据块分别被存到那些数据节点上,主要功能是对内存及 I/O 进行集中管理(是个单点,发生故障将使集群崩溃)(二)DataNode 这个后台程序负责把 HDFS 数据块读写到本地的文件系统,当客户端要读写某个数据时候,先由 NameNode 告诉客户端去哪个 DataNode 进行具体的读/写操作,然后客户端直接与这个 DataNode 服务器上的后台程序进行通讯,并且对相关的数据块进行读/写操作
(三)SecondaryNameNode:是一个用来监控 HDFS 状态的辅助后台程序,就像 NameNode 一样,每个集群都有一个 Secondary NameNode,不接收或记录任何实时的数据变化,但是,他会与 NameNode 进行通信,以便定期的保存 HDFS 元数据的快照,假如 Name 发生