OpenStack 与 Hadoop 被誉为继 Linux之后最有可能获得巨大成功的开源项目
这二者如何结合成为更猛的新方案
业内给出两种答案:Hadoop 跑在 OpenStack 上或 OpenStack部署到 Hadoop 上
Steve Markey教授重点介绍了后者
这两种答案都有企业在实践
“Hadoop 跑在 OpenStack 上”可以参考《Project Savanna:让 Hadoop 运行在 OpenStack 之上》,“OpenStack 部署到 Hadoop 上”则重点可查阅本文
随着企业开始同时利用云计算和大数据技术,现在应当考虑如何将这些工具结合使用
在这种情况下,企业将实现最佳的分析处理能力,同时利用私有云的快速弹性 (rapid elasticity) 和单一租赁的特性
如何协同效用和实现部署,是本文希望解决的问题
一些基础知识 第一是 OpenStack
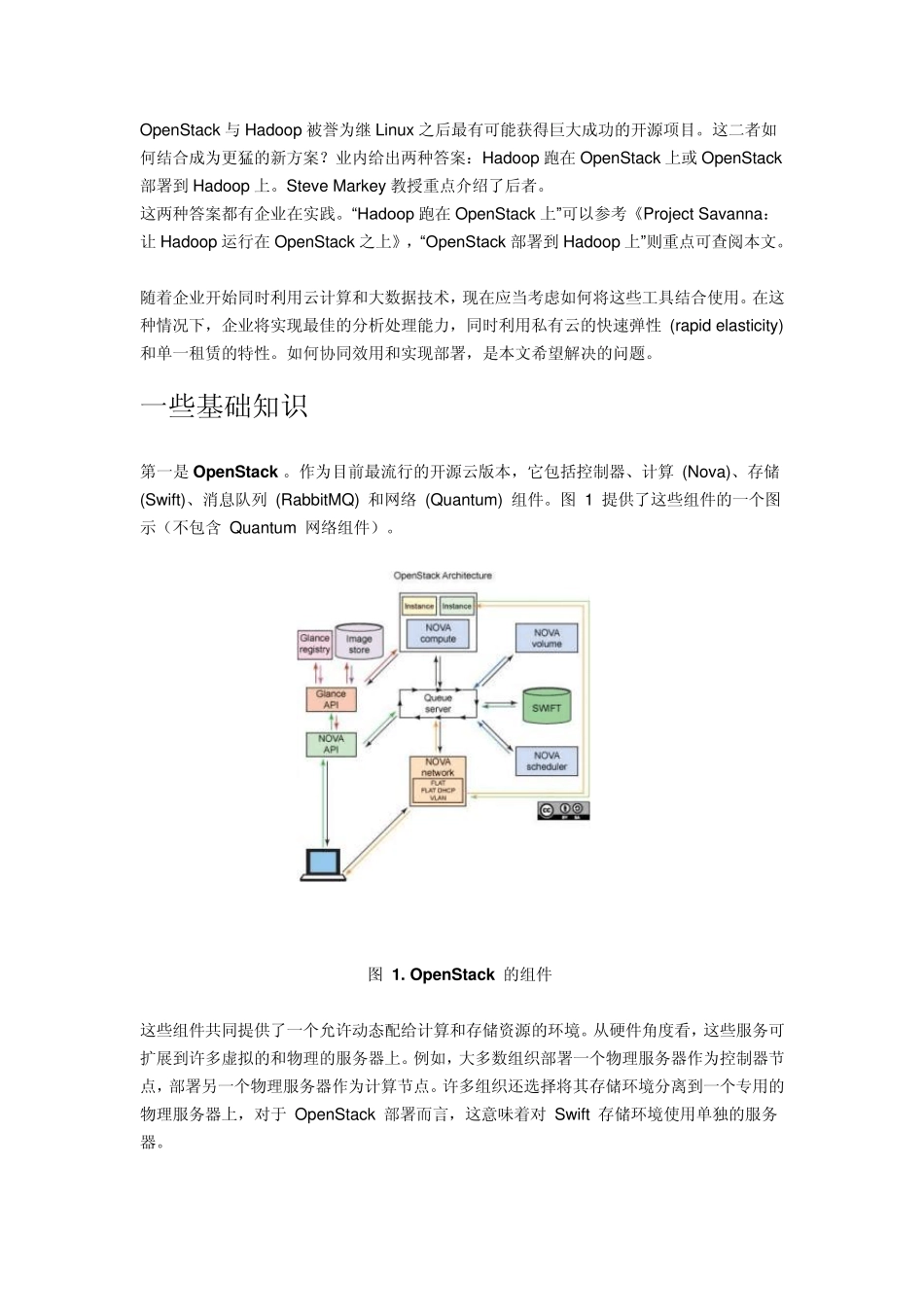
作为目前最流行的开源云版本,它包括控制器、计算 (Nova)、存储 (Swift)、消息队列 (RabbitMQ) 和网络 (Quantum) 组件
图 1 提供了这些组件的一个图示(不包含 Quantum 网络组件)
OpenStack 的组件 这些组件共同提供了一个允许动态配给计算和存储资源的环境
从硬件角度看,这些服务可扩展到许多虚拟的和物理的服务器上
例如,大多数组织部署一个物理服务器作为控制器节点,部署另一个物理服务器作为计算节点
许多组织还选择将其存储环境分离到一个专用的物理服务器上,对于 OpenStack 部署而言,这意味着对 Swift 存储环境使用单独的服务器
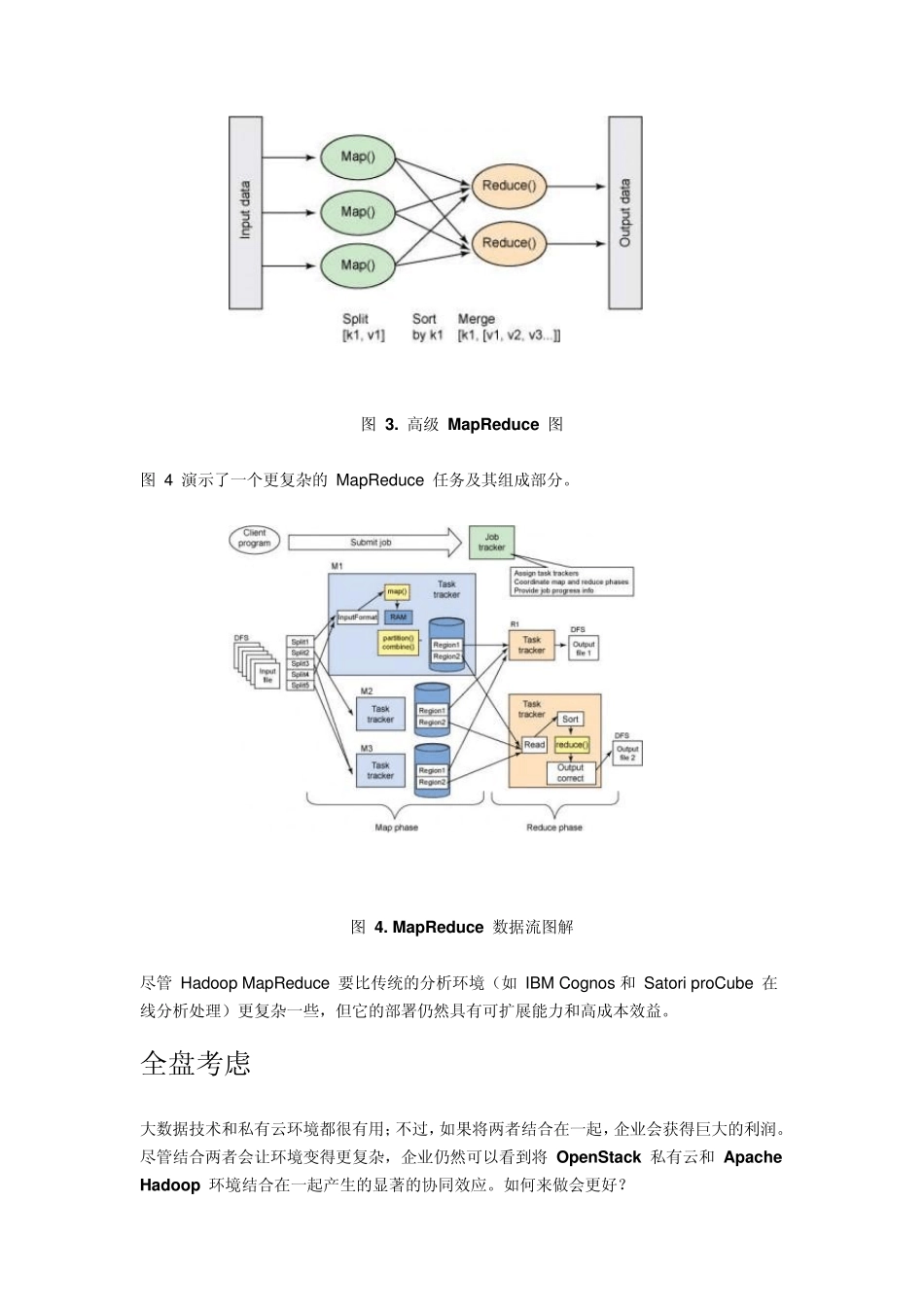
第二是大数据
一般可以理解为三个数据源的数据汇集:传统数据(结构化数据)、感知数据(日志数据和元数据)和社交(社交媒体)数据
大数据通常采用新的技术模式进行存储,比如非关系分布式数据库