树形结构的数据库表Schem a 设计 程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门、栏目结构、商品分类等等,通常而言,这些树状结构需要借助于数据库完成持久化
然而目前的各种基于关系的数据库,都是以二维表的形式记录存储数据信息,因此是不能直接将 Tree 存入DBMS,设计合适的Schema 及其对应的CRUD 算法是实现关系型数据库中存储树形结构的关键
理想中树形结构应该具备如下特征:数据存储冗余度小、直观性强;检索遍历过程简单高效;节点增删改查 CRUD 操作高效
无意中在网上搜索到一种很巧妙的设计,原文是英文,看过后感觉有点意思,于是便整理了一下
本文将介绍两种树形结构的Schema 设计方案:一种是直观而简单的设计思路,另一种是基于左右值编码的改进方案
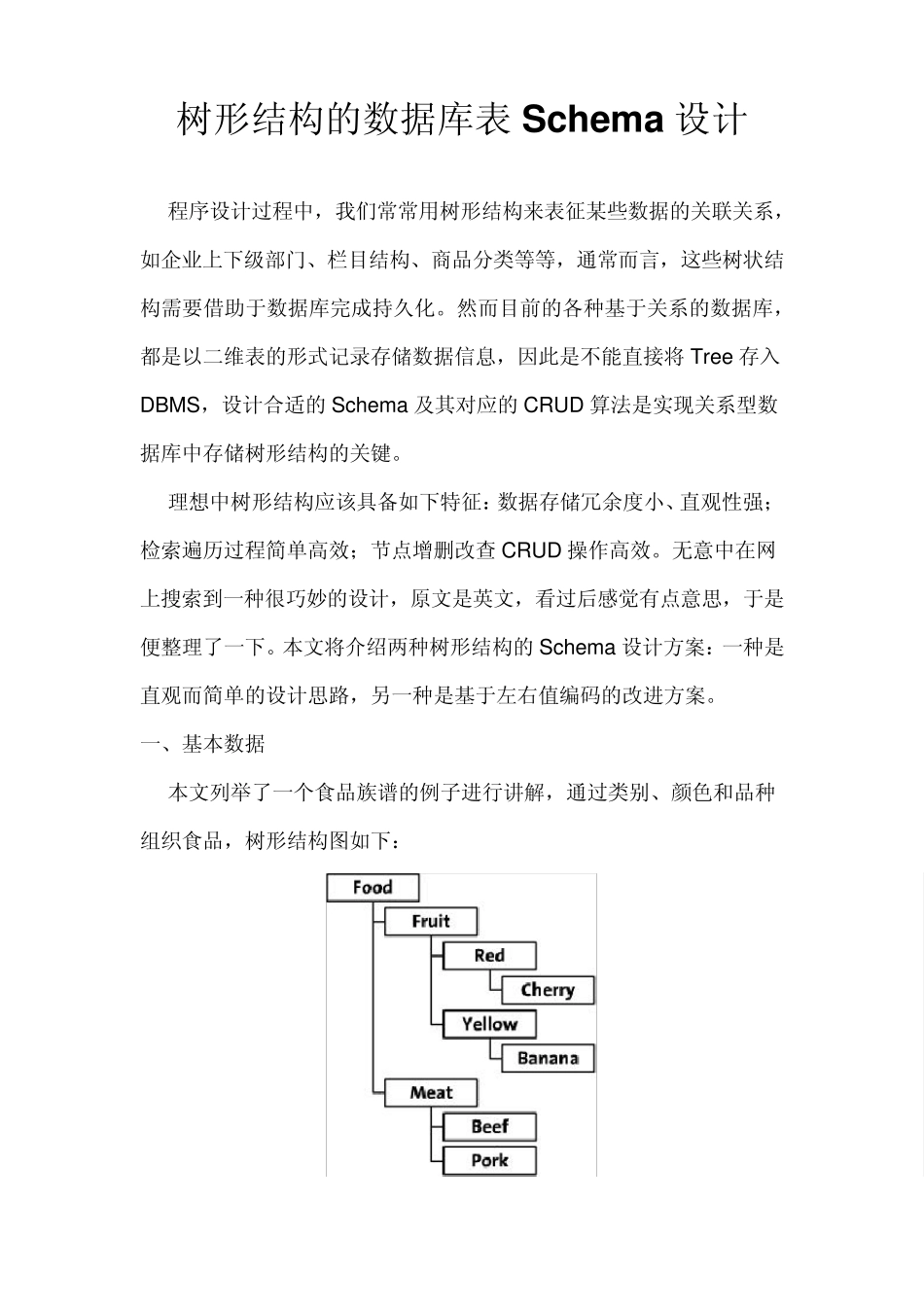
一、基本数据 本文列举了一个食品族谱的例子进行讲解,通过类别、颜色和品种组织食品,树形结构图如下: 二、继承关系驱动的 Schem a 设计 对树形结构最直观的分析莫过于节点之间的继承关系上,通过显示地描述某一节点的父节点,从而能够建立二维的关系表,则这种方案的Tree 表结构通常设计为:{Node_id,Parent_id},上述数据可以描述为如下图所示: 这种方案的优点很明显:设计和实现自然而然,非常直观和方便
缺点当然也是非常的突出:由于直接地记录了节点之间的继承关系,因此对 Tree 的任何 CRUD 操作都将是低效的,这主要归根于频繁的“递归”操作,递归过程不断地访问数据库,每次数据库 IO 都会有时间开销
当然,这种方案并非没有用武之地,在 Tree 规模相对较小的情况下,我们可以借助于缓存机制来做优化,将 Tree 的信息载入内存进行处理,避免直接对数据库 IO 操作的性能开销
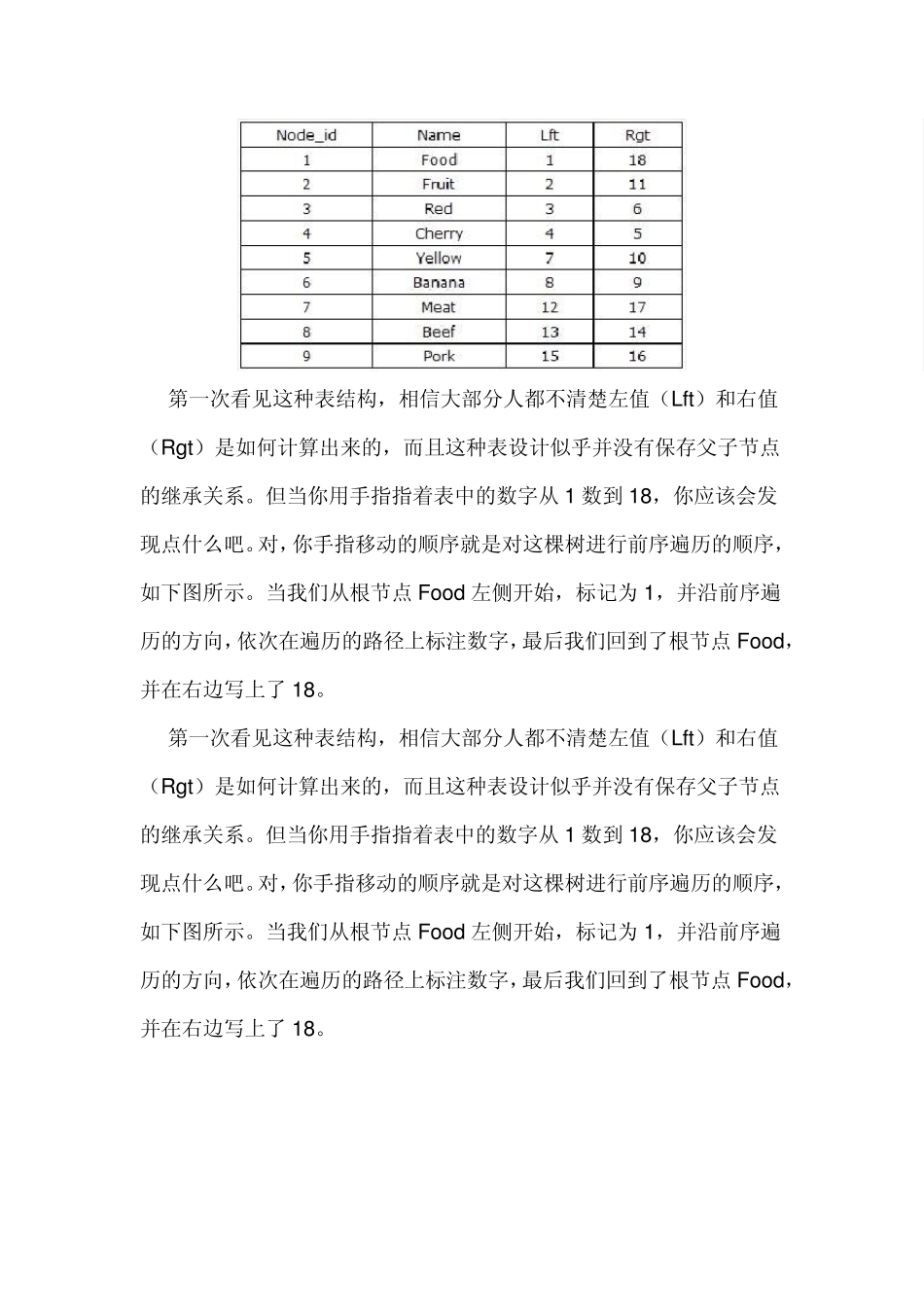
三、基于左右值编码的 Schem a 设计 在基于数据库的一般应用中,查询的需求总要大于