昨日,七牛数据平台工程师就七牛部使用的数据平台,深化分享了该团队在 Flume、Kafka、Spark 以与 Streaming 上的实践经验,并讲解了各个工具使用的注意点
分享人介绍:王团结,七牛数据平台工程师,主要负责数据平台的设计研发工作
关注大数据处理,高性能系统服务,关注Hadoop、Flume、Kafka、Spark 等离线、分布式计算技术
下为讨论实录数据平台在大部分公司属于支撑性平台,做的不好立即会被吐槽,这点和运维部门很像
所以在技术选型上优先考虑现成的工具,快速出成果,没必要去担心有技术负担
早期,我们走过弯路,认为没多少工作量,收集存储和计算都自己研发,发现是吃力不讨好
去年上半年开始,我们全面拥抱开源工具,搭建自己的数据平台
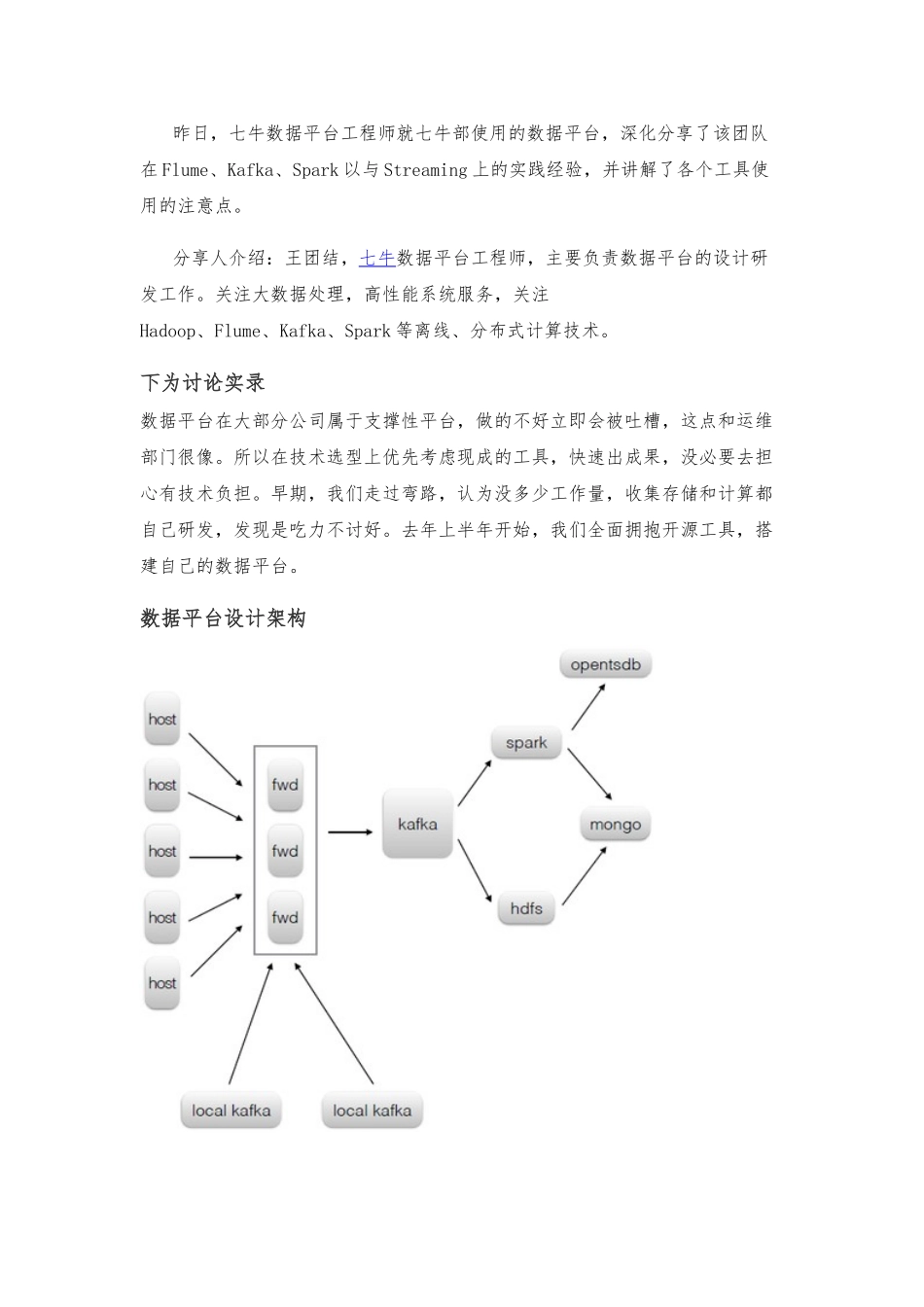
数据平台设计架构公司的主要数据来源是散落在各个业务服务器上的半结构化的日志(系统日志、程序日志、访问日志、审计日志等)
大家有没考虑过为什么需要日志
日志是最原始的数据记录,假如不是日志,肯定会有信息上的丢失
说个简单的例子,需统计 nginx 上每个域名的的流量,这个完全可以通过一个简单的 nginx 模块去完成,但是当我们需要统计不同来源的流量时就法做了
所以需要原始的完整的日志
有种手法是业务程序把日志通过网络直接发送出去,这并不可取,因为网络和接收端并不完全可靠,当出问题时会对业务造成影响或者日志丢失
对业务侵入最小最自然的方式是把日志落到本地硬盘上
Agent 设计需求每台机器上会有一个 agent 去同步这些日志,这是个典型的队列模型,业务进程在不断的 push,agent 在不停的 pop
agent 需要有记忆功能,用来保存同步的位置(offset),这样才尽可能保证数据准确性,但不可能做到完全准确
由于发送数据和保存 offset 是两个动作,不具有事务性,不可避开的会出现数据不一致性情况,通常是发送成功后保存