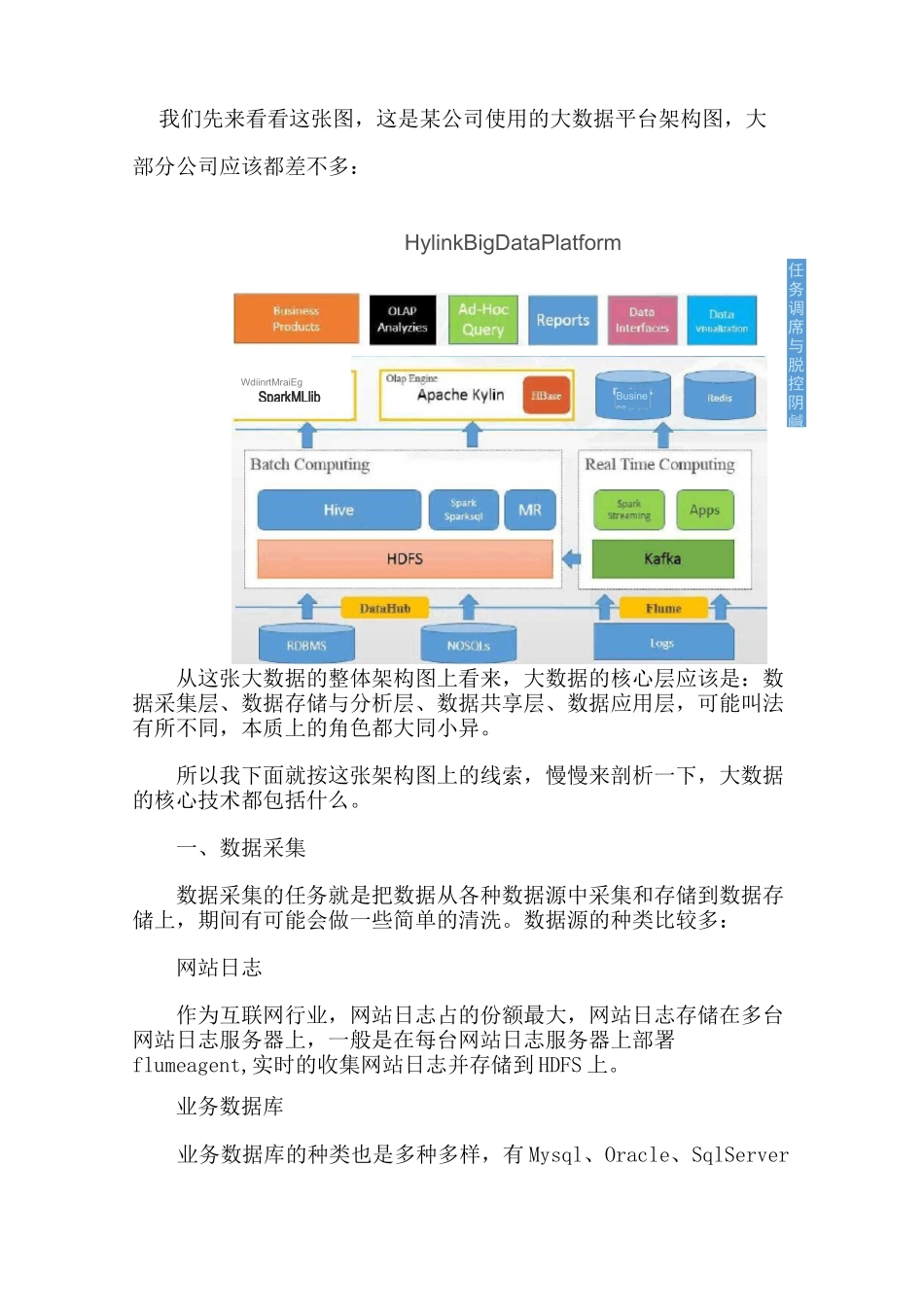
大数据架构和业务处理流我们先来看看这张图,这是某公司使用的大数据平台架构图,大部分公司应该都差不多:HylinkBigDataPlatform从这张大数据的整体架构图上看来,大数据的核心层应该是:数据采集层、数据存储与分析层、数据共享层、数据应用层,可能叫法有所不同,本质上的角色都大同小异
所以我下面就按这张架构图上的线索,慢慢来剖析一下,大数据的核心技术都包括什么
一、数据采集数据采集的任务就是把数据从各种数据源中采集和存储到数据存储上,期间有可能会做一些简单的清洗
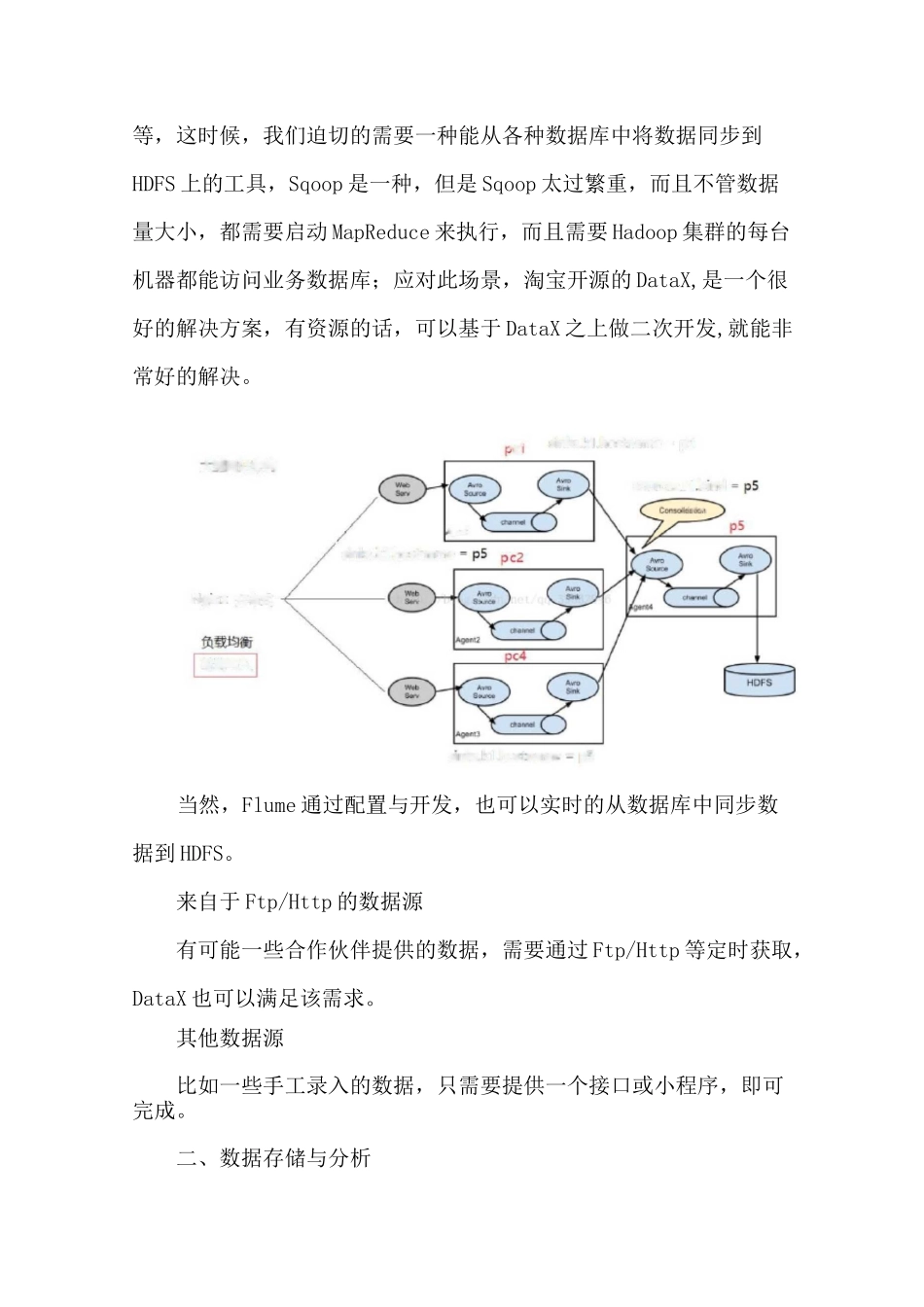
数据源的种类比较多:网站日志作为互联网行业,网站日志占的份额最大,网站日志存储在多台网站日志服务器上,一般是在每台网站日志服务器上部署flumeagent,实时的收集网站日志并存储到 HDFS 上
业务数据库业务数据库的种类也是多种多样,有 Mysql、Oracle、SqlServerWdiinrtMraiEgSparkMLlib任务调席与脱控阴鹹Businessscurces-II■*:,AptfiHsinks
hostnasinks
hostname=p人卑网帖架、十sinks
hostname 二p5Ngmx 分布鞄询写等,这时候,我们迫切的需要一种能从各种数据库中将数据同步到HDFS 上的工具,Sqoop 是一种,但是 Sqoop 太过繁重,而且不管数据量大小,都需要启动 MapReduce 来执行,而且需要 Hadoop 集群的每台机器都能访问业务数据库;应对此场景,淘宝开源的 DataX,是一个很好的解决方案,有资源的话,可以基于 DataX 之上做二次开发,就能非常好的解决
当然,Flume 通过配置与开发,也可以实时的从数据库中同步数据到 HDFS
来自于 Ftp/Http 的数据源有可能一些合作伙伴提供的数据,需要通过 Ftp/Http 等定时获取,DataX 也可以满足该