h a do op 原理浅析及安装经过几天得测试,had oo p分布式系统搭建完毕
首先说一下这几天对 ha d o o p 理论知识得理解,然后说一下安装及碰到得问题
有图有真相 第一:理论知识: 什么就是h a d oop: 由三部分组成:HDF S,MapR ed uc e与 Hb a se
维基百科这样说:一个分布式系统基础架构,由A pac h e 基金会开发
用户可以在不了解分布式底层细节得情况下,开发分布式程序
充分利用集群得威力高速运算与存储
这里面关键就就是高速运算与海量存储
我们首先讲海量存储,这个比较有意思,一会儿再说高速运算
海量存储: H DFS<H ad o op D i s t ributed > 前身来自 g o o g le 得一篇博文,所以自身带有浓厚得互联网色彩,比如读多于写得特性,高度得扩展性
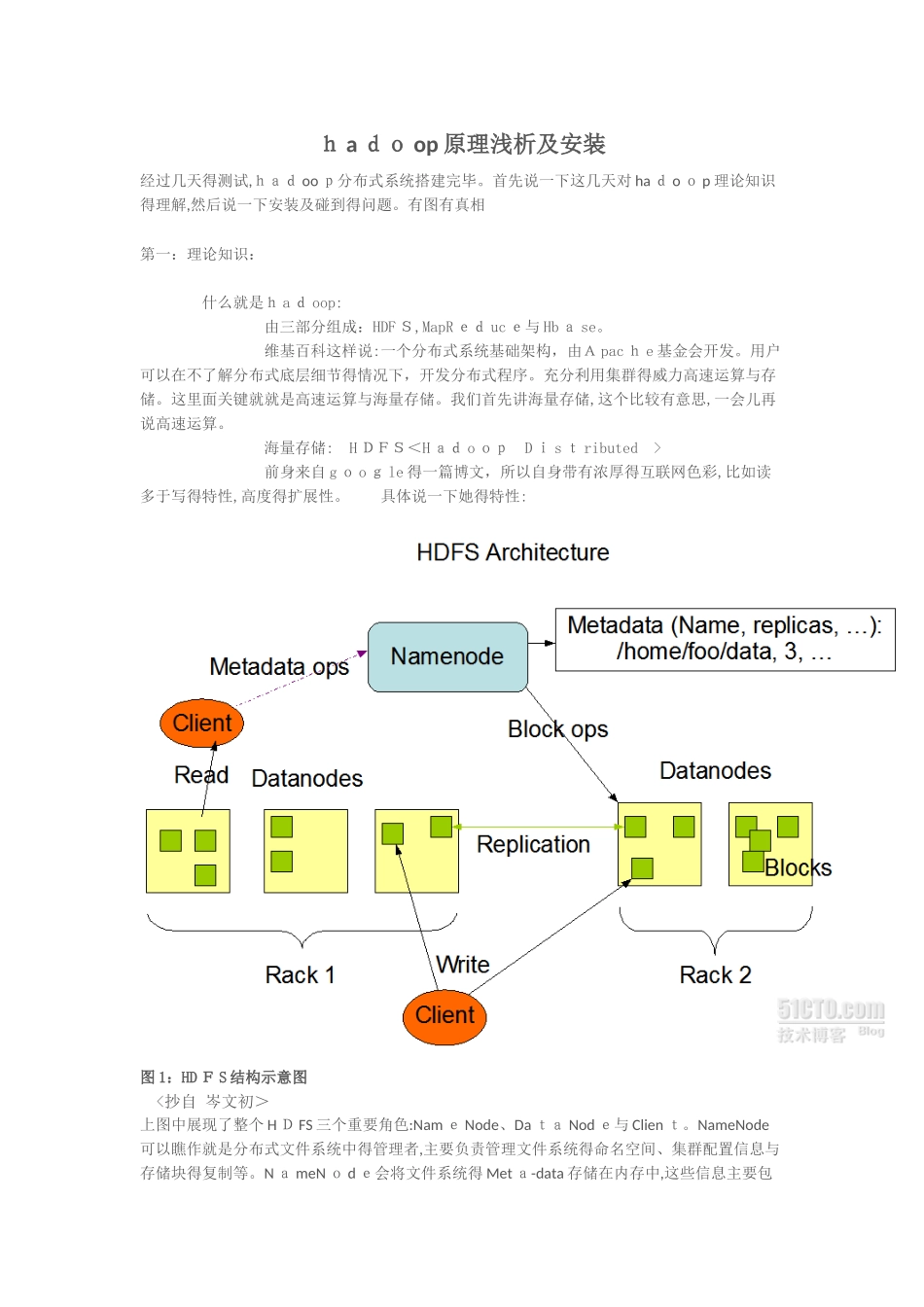
具体说一下她得特性: 图 1:HD F S 结构示意图